
Das Ausführen von LLMs bedeutete früher: Cloud-APIs, Token-Abrechnung und das Vertrauen auf Drittanbieter. Heute gibt es bessere Möglichkeiten wie Ollama: Ollama ist ein Open-Source-Tool, das LLM-Hosting auf eigener Hardware so einfach macht wie jede andere Installation.
Die n8n-Ollama-Integration bietet dir KI-Workflows auf einer Infrastruktur, die du allein kontrollierst. Deine Prompts bleiben lokal. Antworten werden direkt auf deinem VPS generiert. Es gibt keine Nutzungslimits, die dein Budget langsam auffressen. Für Projekte, die KI und Automatisierung ernsthaft angehen, hebt diese Kombination alles auf ein neues Level.
Dieser Guide zeigt dir, was Ollama eigentlich macht und wie die Technik unter der Haube funktioniert inklusive praktischer Schritte, um es in n8n-Workflows einzubinden.
Was ist Ollama: Die Kernkonzepte
Ollama ist eine Open-Source-Plattform, die das lokale Ausführen von Large Language Models (LLMs) vereinfacht. Statt APIs von OpenAI oder Anthropic aufzurufen, lädst du die Modelle auf deinen Server und führst die Inferenz direkt dort aus. Modell-Management, Serving und Optimierung sind bereits integriert, sodass du nicht Wochen damit verbringen musst, diese Infrastruktur selbst aufzubauen.
Die Hauptfeatures von Ollama konzentrieren sich auf die simple Zugänglichkeit. Das Modell-Management funktioniert über einfache Befehle: ollama pull llama3.2 lädt ein Modell herunter, ollama run llama3.2 startet direkt einen Chat. Hinter diesen Befehlen steckt ein API-Server, den andere Anwendungen aufrufen können. Genau das ist dein Integrationspunkt für n8n.
Die Performance von Ollama hängt von deiner Hardware ab, aber das Tool optimiert die Inferenz automatisch. Es jongliert mit dem Laden von Modellen, dem Speichermanagement und der GPU-Nutzung - ganz ohne manuelles Tuning. Ein Modell mit 7B-Parametern läuft bereits auf herkömmlichen Consumer-CPUs recht ordentlich. Größere Modelle profitieren von GPUs, setzen diese aber nicht zwingend voraus.
Hier wird es in Sachen Sicherheit spannend: Die Inferenz findet direkt auf deiner Infrastruktur statt. Deine Prompts landen nie bei externen APIs und die Model-Files liegen sicher auf deiner eigenen Platte. Antworten werden lokal generiert und erreichen niemals fremde Server. Für Teams, die mit sensiblen Daten arbeiten oder strenge Compliance-Vorgaben erfüllen müssen, verändert das das Risikoprofil im Vergleich zu Cloud-LLMs grundlegend. Wir glauben, dass das schwerer wiegt als die meisten Benchmark-Vergleiche.
Die Plattform unterstützt dutzende Modelle wie Llama, Mistral, Gemma und DeepSeek. Sie können mehrere Modelle gleichzeitig ausführen und zwischen ihnen pro Anfrage wechseln, indem Sie die richtige Modellgröße und -fähigkeit für jede Aufgabe auswählen, anstatt alles über einen Endpunkt zu zwingen.
Wie funktioniert Ollama?
Ollama legt los, sobald du ein Modell mit "pull" abrufst. Es lädt die Modell-Dateien herunter, speichert sie lokal und stellt sie dem API-Server zur Verfügung. Sobald eine Anfrage eingeht, lädt Ollama das Modell in den Arbeitsspeicher (oder hält es für weitere Anfragen geladen), führt die Inferenz aus und liefert das Ergebnis zurück.
Wo speichert Ollama die Modelle? Diese liegen in einer ganz bestimmten Verzeichnisstruktur. Unter Linux ist das normalerweise ~/.ollama/models/. Jedes Modell besteht aus den Weight-Dateien, der Konfiguration und Metadaten. Große Modelle können dabei mehrere Gigabyte an Speicherplatz belegen. Speicherplatz ist wichtig, wenn du mehrere Modelle gleichzeitig nutzt.
Der API-Server stellt einen REST-Endpunkt bereit, der deine Prompts annimmt und Antworten liefert. Dieser Endpunkt ist das Bindeglied für Tools wie n8n. Wenn du JSON-Daten mit deinem Prompt und den Parametern sendest, verarbeitet Ollama es durch das Modell und erhältst du Text zurück. Streaming wird ebenfalls unterstützt, sodass Antworten Token für Token eintreffen können, statt dich bis zum Abschluss der gesamten Antwort warten zu lassen.
Das Speichermanagement läuft vollautomatisch. Ollama lädt Modelle bei Bedarf und gibt den Arbeitsspeicher wieder frei, wenn es eng wird. Selbst 8 GB RAM reichen aus, um 7B-Modelle problemlos zu nutzen. Größere Modelle brauchen meist mehr RAM oder quantisierte Versionen.
GPU-Beschleunigung ist optional, aber ein echter Vorteil. Wenn du eine GPU hast, erkennt Ollama diese und lagert die Berechnungen dorthin aus, was die Inferenz bei größeren Modellen massiv beschleunigt. Reine CPU-Inferenz funktioniert für viele Zwecke trotzdem gut, besonders bei kleineren Modellen.
Warum du Ollama auf einem VPS statt in der Cloud nutzen solltest
Cloud-Preismodelle für Ollama basieren meist auf Token- oder Stundenabrechnung, die mit der Nutzung skalieren. Ein Prompt mit 1.000 Wörtern und eine Antwort mit 500 Wörtern kosten vielleicht nur ein paar Cent. Das klingt fair bis du 10.000 Anfragen im Monat hast und plötzlich hunderte Euro zahlst. Selbstgehostetes Ollama auf einem VPS ändert dieses Kostenmodell komplett.
Bei einem Ollama VPS sind deine monatlichen Kosten auf den Server fixiert. Das war's. Egal ob du 100 oder 100.000 Anfragen stellst: Die Rechnung bleibt gleich. Keine nutzungsbasierten Gebühren, die sich heimlich auf deiner Rechnung einschleichen. Keine Schock-Rechnungen bei Traffic-Spitzen, nur weil jemand deine App auf Reddit geteilt hat.
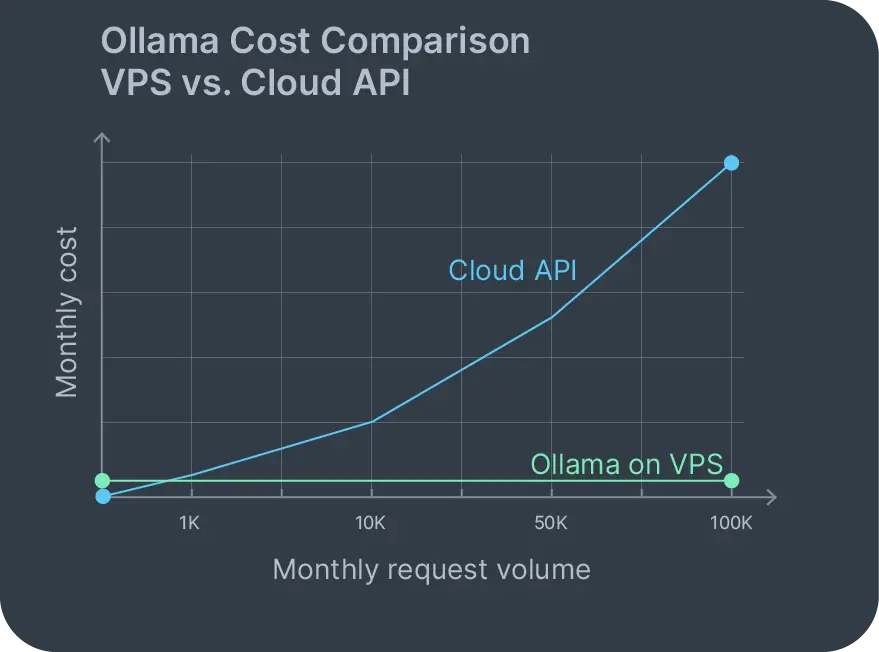
Der Datenschutz ist der andere große Faktor. Es gibt zwar Cloud-Optionen für Ollama, aber die bringen genau das Vertrauensproblem zurück, dem du entkommen wolltest. Wenn du Ollama selbst hostest, verlassen deine Daten niemals deine eigene Infrastruktur. Kundensupport-Tickets, interne Dokumente, proprietärer Code - all das bleibt während der Inferenz auf deinem VPS.
Auch die Compliance wird dadurch deutlich einfacher. Die DSGVO verlangt von dir, dass du weißt, wo genau deine Daten verarbeitet werden. HIPAA schränkt ein, wie geschützte Gesundheitsdaten bewegt werden dürfen. Ollama lokal zu betreiben hält dich innerhalb dieser Grenzen ohne komplexe Datenverarbeitungsverträge mit Cloud-Anbietern auszuhandeln, die diese am Ende vielleicht gar nicht einhalten.
Du kontrollierst auch die Upgrades. Neue Modelle erscheinen am laufenden Band. Bei einem selbstgehosteten Setup lädst du das neue Modell einfach herunter und kannst es sofort testen. Kein Warten darauf, dass Cloud-Anbieter es endlich ins Sortiment aufnehmen. Kein Vendor-Lock-in, der bestimmt, auf welche Modelle du wann Zugriff hast.
Hardware ist entscheidend für KI-Workloads - du brauchst genug CPU-Kerne, RAM und idealerweise GPU-Zugriff. Contabo bietet eine Reihe von Server-Plänen, die für KI und Machine Learning optimiert sind mit Konfigurationen, die ideal für den Betrieb mehrerer Modelle und parallele Inferenz-Anfragen sind. Du kannst Ollama natürlich auf jedem VPS, VDS oder Dedicated Server deiner Wahl laufen lassen.
Die Wahl des richtigen Ollama-VPS-Anbieters
Um Ollama erfolgreich auf einem VPS zu betreiben, muss die Hardware zu deinem Workload passen. Das absolute Minimum ist ein Setup wie unser Cloud VPS 10 mit 4 vCPUs, 8 GB RAM und 75 GB Speicher. Das reicht aus, um 7B-Parameter-Modelle vernünftig zu betreiben. Für ein flüssigeres Erlebnis, empfiehlt sich ein Upgrade auf den Cloud VPS 30 der auch größere Modelle packt und mehrere Anfragen gleichzeitig ohne Engpässe verarbeitet.
Speicherplatz ist wichtig, da die Modelle riesig sind. Llama3 7B braucht etwa 4 GB. Mixtral 8x7B geht schon Richtung 50 GB. Du nutzt mehrere Modelle? Dann summiert sich der Speicherbedarf schnell. NVMe-Laufwerke helfen enorm mit dem Laden der Modelle, was wiederum die Latenz verringert, wenn ein inaktives Modell erst "hochfahren" muss.
Eine GPU ist kein Muss, aber sie hebt die Leistung spürbar an. Eine Mittelklasse-GPU wie die A4000 verkürzt die Inferenzzeit bei großen Modellen massiv. In produktiven Workflows mit vielen Nutzern rechtfertigen GPUs definitiv ihren Preis. Für interne Tools mit weniger Traffic reicht CPU-Inferenz völlig aus. Schau dir die Contabo GPU-Cloud an, um zu sehen, wie du deinen Server aufrüsten kannst.
Die Netzwerkbandbreite ist vor allem für das initiale Setup wichtig. Das Abrufen großer Modelle bedeutet, dass etliche Gigabytes über die Leitung geladen werden müssen. Danach benötigt die lokale Inferenz keine Internetverbindung mehr - außer du verbindest dich über n8n mit externen Diensten. Trotzdem profitierst du beim ersten Download von schnellen Leitungen, die nicht mittendrin drosseln.
Es ergibt Sinn, Ollama parallel zu anderen selbstgehosteten Tools zu betreiben. Kombiniere deine selbstgehostete Nextcloud als Speicher mit Ollama für die Dokumentenanalyse. Pack noch n8n für die Workflow-Automatisierung oben drauf. Installiere alles auf einer Nextcloud-VPS-Instanz, falls die Ressourcen reichen, oder verteile es auf mehrere Server, je nach Last und gewünschter Isolierung. Beide Apps sind auf jedem Contabo VPS oder VDS per kostenloser 1-Klick-Installation verfügbar.
Schritt-für-Schritt: Ollama auf einem VPS bereitstellen
Die Installation von Ollama auf Linux ist denkbar einfach. Logge dich per SSH auf deinem VPS ein und starte das Installationsskript:
curl -fsSL https://ollama.com/install.sh | sh Das lädt Ollama herunter, installiert es und startet den Dienst. Auf Ubuntu, Debian und den meisten modernen Linux-Distros läuft das ohne weitere Abhängigkeiten.
Prüfe nach der Installation, ob Ollama läuft:
ollama --version Du solltest jetzt die Versionsnummer sehen. Jetzt rufst du dein erstes Modell ab:
ollama pull llama3.2 Das lädt Llama 3.2 (7B Parameter) herunter und speichert es lokal. Die Downloadzeit hängt von deiner Internetgeschwindigkeit und der Modellgröße ab. Llama 3.2 ist etwa 4 GB groß - stell dich also auf ein paar Minuten Wartezeit ein.
Wie du Ollama nach dem Abrufen eines Modells ausführst:
ollama run llama3.2 Dies startet eine interaktive Sitzung, in der du Prompts testen kannst. Tippe eine Frage ein, drücke Enter und schau zu, wie die Antwort per Stream eintrifft. Beende die Sitzung mit /bye.
Um DeepSeek mit Ollama auf einem VPS auszuführen, ist der Vorgang identisch:
ollama pull deepseek-coder
ollama run deepseek-coder DeepSeek-Modelle sind auf Code-Generierung und -Analyse spezialisiert. Lokales Hosting bedeutet, dass dein eigener Quellcode während der Analyse niemals deine Infrastruktur verlässt. Das ist ein riesiger Vorteil, wenn du mit Daten arbeitest, bei denen deine Rechtsabteilung sonst nervös würde.
Wo speichert Ollama die Modelle auf deinem System? Prüfe den Standardpfad:
ls ~/.ollama/models Jedes Modell liegt in einem eigenen Unterverzeichnis inklusive Weights, Konfiguration und Metadaten. Musst du den Speicherplatz verwalten? Genau hier sammeln sich die Modelle an.
Der API-Server startet automatisch und lauscht standardmäßig auf localhost:11434. Teste es mit curl:
curl http://localhost:11434/api/generate -d '{
"model": "llama3.2",
"prompt": "Why is the sky blue?"
}'Du solltest eine JSON-Antwort erhalten, in der der generierte Text zurückgestreamt wird. Diesen Endpunkt nutzt n8n später für die Integration.
Für den Produktiveinsatz solltest du Ollama hinter einem Reverse-Proxy betreiben, falls du externen Zugriff benötigst. Aber Für die n8n-Integration auf demselben VPS ist der lokale Zugriff völlig ausreichend und sicherer, da du so keine Ports unnötig nach außen freigeben musst.
Wenn du dich speziell für DeepSeek-Modelle im Unternehmenseinsatz interessierst, bietet Contabo auch selbstgehostete DeepSeek-KI-Lösungen an, die für optimale Leistung maßgeschneidert sind.
Voraussetzungen für die n8n-Ollama-Integration auf einem VPS
Bevor du die n8n-Ollama-Integration einrichtest, müssen beide Tools installiert und erreichbar sein. Ollama läuft bereits, wenn du den vorherigen Abschnitt befolgt hast. Installiere jetzt n8n.
Der schnellste Weg führt über Docker:
docker run -d --name n8n \
-p 5678:5678 \
-v ~/.n8n:/home/node/.n8n \
n8nio/n8n Oder installiere es alternativ über npm:
npm install n8n -g
n8n start Sobald n8n läuft, kannst du darauf zugreifen unter: http://your-vps-ip:5678. Erstelle ein Konto. Schon bist du bereit, Workflows zu erstellen.
Du kannst n8n auch über unsere kostenlose 1-Klick-Option installieren, beachte aber, dass dies zuerst auf einem neuen Server eingerichtet werden muss (oder über eine Neuinstallation, die bestehende Daten löscht), gefolgt von der manuellen Ollama-Installation wie oben beschrieben. Erfahre auf der Contabo Webseite mehr über das Self-Hosting von n8n auf einem Contabo VPS.
Für die Integration von Ollama in n8n musst du den Netzwerkzugriff sicherstellen. Laufen beide Dienste auf demselben VPS, ist die Ollama-API unter bereits erreichbar. Teste das aus n8n-Sicht, indem du einen einfachen HTTP-Request-Workflow erstellst:
- Füge einen "Manual Trigger"-Knoten hinzu.
- Füge einen "HTTP Request"-Knoten hinzu.
- Setze die Methode auf POST.
- URL:
http://localhost:11434/api/generate - Body: JSON mit Modellname und Prompt.
- Führe den Workflow aus.
Wenn die Antwort generierten Text enthält, steht die Verbindung. Falls es fehlschlägt, prüfe, ob der Ollama-Dienst läuft (systemctl status ollama) und auf dem richtigen Port lauscht.
Die Verbindung wird mit den speziellen Ollama-Knoten von n8n sogar noch einfacher. Statt HTTP-Requests manuell zu bauen, kannst du den "Ollama-Chat Model"-Knoten nutzen.
Beispiel-Workflow: Aufgaben mit n8n und Ollama automatisieren
Ein n8n-Ollama-Workflow wird erst dann richtig nützlich, wenn beide Dienste miteinander kommunizieren. Hier ist ein Praxisbeispiel: automatisierte E-Mail-Analyse und Antwortgenerierung für den Kundensupport.
Die Workflow-Struktur:
- Ein E-Mail-Trigger-Knoten überwacht ein Postfach
- Extrahiert Inhalte aus neuen E-Mails
- Sendet E-Mail-Inhalte mit einer Aufforderung (Prompt) an Ollama
- Analysiert Antwort von Ollama
- Leitet an die entsprechende Aktion weiter
In n8n sieht das so aus:
Triggerknoten: E-Mail-Trigger (IMAP)
- Konfiguriere ihn zur Überwachung von [email protected].
- Auslösen bei neuen ungelesenen Nachrichten.
Ollama-Chatmodell-Knoten:
- Modell: llama3.2
- Aufforderung: "Analysiere diese Kundensupport-E-Mail und generiere eine Antwort. E-Mail: {{$json.body}}"
- Temperatur: 0,7 für ausgewogene Kreativität.
IF-Knoten: Überprüfe die Antwort.
- Komplexes Problem? Leite an einen Menschen weiter.
- Ist der Fall eindeutig? Bereite eine automatisierte Antwort vor.
"Send Email"-Knoten: Sende die generierte Antwort.
- Wird nur bei eindeutigen Fällen ausgeführt.
- Enthält den Hinweis, dass die Antwort KI-generiert wurde.

Dieser n8n-Ollama-Workflow läuft vollständig auf deinem VPS. Kunden-E-Mails gelangen niemals auf externe APIs. Generierte Antworten bleiben lokal, bis du sie ausdrücklich verschickst. Dein Support-Postfach wird nicht zu Trainingsdaten für die Modelle anderer Anbieter.
Ollama mit n8n für diese Workflows zu nutzen bedeutet, gezielt über Aufforderungen und Parameter nachzudenken. Die Temperatur steuert die Kreativität. Höhere Werte erzeugen variablere Ergebnisse, während niedrigere Werte zu deterministischeren (eindeutigeren) Resultaten führen. Die Kontextlänge begrenzt, wie viel Text du pro Anfrage senden kannst. Die Wahl des Modells beeinflusst sowohl die Fähigkeiten als auch die Geschwindigkeit.
Workflows zur Content-Moderation funktionieren ebenfalls hervorragend. Überwache Chat-Anwendungen, filtere Nachrichten durch Ollama, um problematische Inhalte zu erkennen und sie zur Überprüfung zu markieren. Das alles geschieht lokal. Sensible Kommunikation verlässt während der Moderation nicht deine Infrastruktur – das ist besonders wichtig bei Mitarbeitergesprächen oder Kundenbeschwerden.
Die Erstellung von Social-Media-Inhalten ist eine weitere praktische Anwendung. Plane Trigger, sende Aufforderungen basierend auf deinem Redaktionsplan an Ollama, generiere verschiedene Beitrags-Varianten und speichere sie zur Prüfung ab. Marketing-Teams können Content-Varianten in Serie generieren, ohne dass Token-Gebühren ihr Budget auffressen.
Selbstgehostetes Ollama in n8n-Workflows nimmt die nutzungsbasierte Abrechnung komplett aus der Gleichung. Experimentiere nach Belieben. Überarbeite deine Aufforderungen dutzende Male. Verarbeite hohe Volumina auch in Spitzenzeiten. Deine Kosten bleiben fix bei der VPS-Hosting-Gebühr.
Ollama FAQ
Wie installiert man Ollama auf Linux?
Führe das Installationsskript aus: curl -fsSL https://ollama.com/install.sh | sh.. Dies installiert Ollama und startet den Dienst auf den meisten Linux-Distributionen automatisch. Überprüfe die Installation nach Abschluss mit ollama --version.
Wie führt man Ollama aus?
Nachdem du ein Modell mit ollama pull model-name abgerufen hast, starte es mit ollama run model-name für interaktives Testen oder rufe die API auf unter http://localhost:11434/api/generate für den programmgesteuerten Zugriff. Dieser API-Ansatz ist genau das, was n8n-Workflows verwenden.
Wo speichert Ollama die Modelle?
Modelle werden auf Linux-Systemen im ~/.ollama/models/ Verzeichnis gespeichert. Jedes Modell belegt je nach Parameteranzahl und Quantisierung mehrere Gigabyte an Speicherplatz. Überprüfe dieses Verzeichnis, wenn du den Speicherplatz verwaltest oder Probleme mit fehlenden Modellen behebst.
Wie verbindet man Ollama mit n8n?
Installiere beide Tools auf demselben VPS. Ollama lauscht standardmäßig auf diesem Port localhost:11434. Verwende in n8n den Ollama-Chatmodell-Knoten und konfiguriere ihn so, dass er auf die lokale Adresse zeigt. http://localhost:11434. Teste die Verbindung mit einem einfachen Workflow, bevor du komplexe Automatisierungen erstellst.
Wie verwendet man Ollama mit n8n?
Erstelle Workflows mit dem visuellen Editor von n8n. Füge einen Ollama-Chatmodell-Knoten hinzu, konfiguriere dein Modell sowie deine Aufforderung und verbinde ihn dann mit Trigger-Knoten (Webhooks, Zeitpläne, Dateiwächter) und Aktions-Knoten (E-Mail senden, Datenbank aktualisieren, an API posten). Aufforderungen können Variablen aus vorherigen Workflow-Schritten enthalten, um dynamische Inhalte zu generieren.
Fazit
Ollama macht die lokale Bereitstellung von LLMs für Teams zugänglich, die keine Experten für Machine-Learning-Infrastruktur sind. In Kombination mit der Workflow-Automatisierung von n8n erstellst du KI-gestützte Systeme, die vollständig auf deiner eigenen Hardware laufen.
Fixe Kosten. Daten, die deinen VPS niemals verlassen. Modelle, über die du die volle Kontrolle hast. Diese Vorteile wiegen schwerer als theoretische Leistungs-Benchmarks oder Feature-Listen in Marketing-Präsentationen.
Die Vor- und Nachteile von Ollama sind klar verteilt. Vorteile: Planbare Kosten, Datenschutz, einfachere Compliance und die Freiheit, ohne Nutzungslimits zu experimentieren. Nachteile: Du verwaltest die Infrastruktur, die Leistung hängt von deiner Hardware ab und du bist selbst dafür verantwortlich, die Modelle aktuell zu halten. Für die meisten Teams, die auf einem VPS selbst hosten, sprechen diese Abwägungen eindeutig für die lokale Bereitstellung.
Selbstgehostetes Ollama in Kombination mit n8n ermöglicht Workflows, die keine Daten leaken und dich nicht mit API-Rechnungen überraschen. Automatisierung im Kundensupport, Dokumentenanalysen, Content-Erstellung und Code-Reviews finden alle lokal statt - auf Servern, für die du sowieso bezahlst.
Ollama VPS Die Anforderungen für einen Ollama-VPS sind unkompliziert: Du brauchst eine angemessene CPU oder GPU je nach Modellwahl, genügend RAM für die ausgewählten Modelle und ausreichend Speicherplatz für die Dateien. Wie bereits erwähnt, bietet Contabo Konfigurationen an, die ideal für diese Workloads und den Betrieb großer Modelle geeignet sind.
Beide Tools auf demselben VPS laufen zu lassen, hält die Netzwerklatenz minimal und vereinfacht die Bereitstellung erheblich. Egal, ob du interne Dokumente verarbeitest, Kundenantworten generierst oder eigene KI-Copiloten entwickelst – die n8n-Ollama-Integration bietet dir alle Bausteine, um dies ohne externe Abhängigkeiten oder Anbieterbindung umzusetzen.
Die Infrastruktur steht bereit. Die Tools sind Open Source. Deine KI-Workflows können lokal, privat und zu fest kalkulierbaren Kosten laufen. Beginne jetzt damit, Ollama in deine Automatisierungen zu integrieren, und entdecke die Möglichkeiten.
