
Die Entscheidung zwischen LlamaIndex und LangChain geht weniger darum, das „bessere“ Framework auszuwählen, sondern vielmehr darum zu verstehen, welches besser zu deiner Art des Entwickelns passt. Beide helfen dir beim Übergang von reinen Sprachmodellen zu produktiven KI-Systemen, sie befinden sich jedoch auf unterschiedlichen Ebenen des Systems und zeichnen sich an unterschiedlichen Stellen aus.
Dieser LlamaIndex vs. LangChain-Guide verfolgt einen praktischen Ansatz. Wir behandeln Architektur, Abrufmuster, Leistungskompromisse, Tools und die Funktionsweise jedes Frameworks mit dem selbstgehosteten n8n auf einem VPS. Am Ende wirst du wissen, ob dein Projekt primär Orchestrierungstools, datenbasierte Infrastruktur oder beides gleichzeitig benötigt.
Entwickler bewerten LlamaIndex vs. LangChain auf zwei unterschiedliche Weisen. Entweder benötigen sie Hilfe bei der Orchestrierung von Eingabeaufforderungen, Tools und mehrstufigen Entscheidungsprozessen oder sie benötigen eine zuverlässige Möglichkeit, ein LLM mit privaten Dokumenten und Datenbanken zu verbinden. LangChain setzt auf Orchestrierung und Agenten. LlamaIndex (ehemals GPT Index) ist ein Daten-Framework, das entwickelt wurde, um die Bereitstellung und den Betrieb der Retrieval-Augmented Generation zu vereinfachen.
Im Jahr 2026 setzen Teams nur noch selten Rohmodelle ein. Sie verwenden Frameworks, um LangChain-Ketten, Speicher, Abrufpipelines und Auswertungen zu verwalten. Sobald du verstehst wie LlamaIndex und LangChain Kontext, Agenten und Tools verwenden, bist du in der Lage zu entscheiden, ob du mit einem der beiden oder gleich mit beiden von Anfang an starten möchtest.
Die meisten realen Projekte setzen keine Entweder-Oder-Entscheidung voraus. Viele Produktionsstacks verwenden LlamaIndex als Wissensschicht, LangChain als Orchestrierungsschicht und n8n als Workflow-Engine, die sie auf einem VPS oder Dedicated Server verbindet.
Was ist LangChain?
LangChain ist ein Framework zum Erstellen von LLM-basierten Anwendungen, die Sprachmodelle mit Tools, Datenquellen und mehrstufigen Workflows verbinden. Es handelt sich um ein Toolkit, das komplexes KI-Verhalten in zusammensetzbare Bausteine zerlegt, anstatt alles in eine riesige Eingabeaufforderung zu packen.
Diese Bausteine sind die LangChain-Komponenten. Zu den häufigsten gehören Modelle, Prompt-Vorlagen, Speicher, Retriever und Ausgabeparser. Du kombinierst sie zu LangChain-Ketten, wobei jeder Schritt ein LLM oder Tool verwendet, um die Aufgabe voranzubringen. Eine Kette könnte Dokumente abrufen, sie zusammenfassen, eine Antwort generieren und dann das Ergebnis protokollieren. Jedes Stück verbindet sich mit dem nächsten, genau wie die Glieder einer Kette.
An der Spitze der Ketten sitzen LangChain-Agenten. Diese führen die Entscheidungsfindung ein. Ausgehend von einem Ziel und einer Reihe von Tools wählt ein Agent aus, welches Tool als Nächstes aufgerufen werden soll, beobachtet die Ausgabe und wiederholt dies, bis die Aufgabe erledigt ist. Agenten arbeiten gut, wenn Aufgaben verzweigte Logik, externe APIs und mehrstufiges Denken beinhalten, die du im Voraus nicht vorhersagen kannst.
LangChain-Prompts und -Vorlagen definieren, wie du Anfragen an das Modell strukturierst. Anstatt Propts fest zu codieren, erstellst du Vorlagen mit variablen Parametern, die während der Ausführung befüllt werden. Dadurch werden Prompts wiederverwendbar und einfacher zu versionieren. LangChain-Modelle sind modular: OpenAI, Anthropic, Google oder lokale LLMs fügen sich alle in dieselbe Abstraktion ein, sodass du Kosten und Leistung anpassen kannst, ohne deine Pipeline neu schreiben zu müssen.
Die Installation von LangChain passt zu normalen Python- oder node.js-Workflows. Du fügst es über Python- oder node.js-Manager hinzu, konfigurierst Modellanbieter mithilfe von Umgebungsvariablen oder Konfigurationsdateien und vernetzt dann Ketten oder Agenten mit deinen Diensten. Von dort aus stellst du sie hinter APIs bereit, die n8n oder andere Workflow-Tools aufrufen können.
Was ist LlamaIndex?
Während der Fokus von LangChain auf der Orchestrierung liegt, legt ihn LlamaIndex auf Daten. Es fungiert als Daten-Framework für die Verbindung deiner Dokumente, Datenbanken und APIs mit LLMs mithilfe flexibler Indexe und Abfrage-Engines. Es unterstützt Retrieval-Augmented-Generation, indem es deine Inhalte in strukturiertes Wissen umwandelt, das das Modell zuverlässig abfragen kann.
Die Hauptkomponenten von LlamaIndex sind Datenkonnektoren, Knotenparser, Indexe und Abfrage-Engines. Du nimmst Daten aus Quellen wie S3, Postgres, Dateisystemen oder APIs auf, teilst sie in Knoten auf und erstellst dann Indexe. Diese können Vektorindexe, Listenindexe, Baumindexe, Schlüsselwortindexe und Diagrammindexe umfassen. Jede dieser Varianten geht einen anderen Kompromiss zwischen Geschwindigkeit, Genauigkeit und Komplexität ein.
Während die Abfrage ausgeführt wird, leitet LlamaIndex diese über diese Indexe weiter und synthetisiert Antworten. Das Framework übernimmt die Auswahl von Segmenten, das Ranking und die Kontextzusammenstellung, sodass du relevante Passagen im Kontextfenster des Modells erhältst, ohne die Pipeline jedes Mal manuell erstellen zu müssen.
Neuere Versionen fügen außerdem LlamaIndex-Agenten hinzu, die mehrstufige Pläne über deine Indexe und Tools ausführen. Das Framework behält jedoch weiterhin den Datenzugriff und -abruf im Mittelpunkt. Wenn dein größtes Problem „Ich habe viele Dokumente und benötige genaue Antworten“ lautet, dann ist LlamaIndex normalerweise der beste Startpunkt.
LangChain-Kontext und LangChain-Modelle können in LlamaIndex-Retriever integriert werden und viele Teams führen beide Frameworks parallel aus. LangChain übernimmt die Orchestrierung und das Routing von Tools, während sich LlamaIndex um die Datenbeschaffung, die Indizierung und den Abruf kümmert. Diese Arbeitsteilung funktioniert gut, wenn du sowohl Flexibilität als auch Zuverlässigkeit benötigst.
LlamaIndex bietet auch verschiedene Indextypen für verschiedene Anwendungsfälle an. Vektorindexe eignen sich gut für semantische Suchen. Baumindexe sind für hierarchische Dokumente optimiert. Keyword-Indexe meistern Suchen basierend auf exakten Übereinstimmungen. Du wählst den Indextyp auf Basis deiner Datenstruktur und deinen Abfragemustern aus und lässt dann das Framework den Abruf und die Antwortsynthese optimieren.
LangChain vs. LlamaIndex: Grundlegende Unterschiede der Architektur
Wenn man LangChain mit LlamaIndex vergleicht, muss man sich ansehen, wie sie jeweils eine KI-Anwendung strukturieren. LangChain basiert auf Prompts, Tools und Agenten. LlamaIndex basiert auf Datenkonnektoren, Indexen und Abfrage-Engines. Beide können zu ähnlichen Endergebnissen führen, aber sie gehen dabei unterschiedliche Wege.
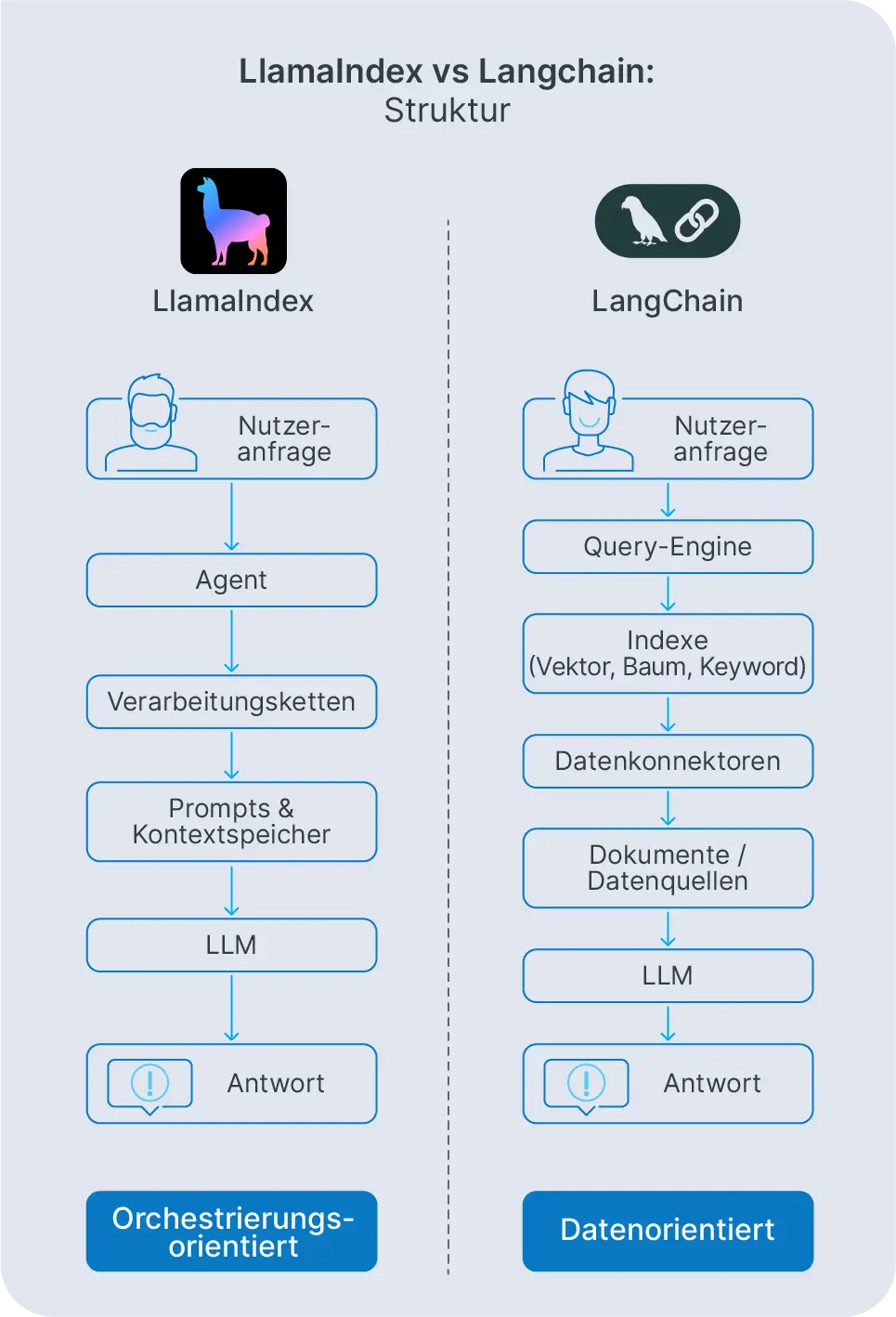
LangChain-Prompts und -Vorlagen legen fest, wie du mit dem Modell kommunizierst. Diese Prompts sind in LangChain-Ketten eingebunden, die Aufrufe an Modelle, Tools und Retriever orchestrieren, häufig mit Speicherfunktionen, die den Gesprächsverlauf oder benutzerspezifischen Kontext aufbewahren. Ketten werden sequentiell oder bedingt ausgeführt, je nachdem, wie du sie konfigurierst.
LangChain-Modelle sind modular einsetzbar. Du tauschst OpenAI gegen Anthropic oder Google aus, ohne die Anwendungslogik neu zu schreiben. Diese Abstraktion ist wichtig, wenn du Kosten optimierst oder neue Modelle testest. Du änderst eine Konfigurationszeile, anstatt deine gesamte Code-Basis umzugestalten.
LangChain-Agenten sitzen an der Spitze von Ketten. Diese Agenten entscheiden, welches Tool als nächstes aus einer Reihe von Optionen aufgerufen wird: Websuche, Datenbankabfragen, benutzerdefinierte APIs oder Dateioperationen. Sie zeichnen sich aus, wenn Aufgaben Verzweigungslogik und externe Tools beinhalten, wie Forschungsassistenten, Operations-Bots oder Kopiloten für den Kundensupport.
LlamaIndex geht einen anderen Weg. LlamaIndex-Agenten und Abfrage-Engines basieren auf Indexen. Anstatt viele Tools zu orchestrieren, orchestrieren sie, wie auf deine Daten zugegriffen wird: welcher Index abgefragt werden soll, wie Ergebnisse kombiniert werden und wie endgültige Antworten generiert werden. Der Schwerpunkt liegt weiterhin auf der Abruf- und Wissensverwaltung und nicht auf der allgemeinen Orchestrierung.
LangChain kann in LlamaIndex-Retriever integriert werden und LlamaIndex kann in LangChain-Agenten ausgeführt werden. Viele Produktionssysteme nutzen beide. Aber wenn man herauszoomt, ist LangChain in erster Linie eine Orchestrierungs-Engine, während LlamaIndex in erster Linie eine Daten- und Abruf-Engine ist. Teams, die sowohl Flexibilität als auch fundierte Antworten benötigen, setzen diese in der Regel gemeinsam ein, anstatt eine Entweder-Oder-Entscheidung zu erzwingen.
LlamaIndex vs. LangChain: Abruf, Kontext und Leistung
Der Abruf und die Kontextverarbeitung steigern die Leistung von LangChain und LlamaIndex in der Praxis mehr als jede einzelne Modellauswahl. Beide Frameworks können RAG unterstützen, aber sie strukturieren die Funktionsweise unterschiedlich und gehen unterschiedliche Kompromisse ein.
In LangChain erstellst du LangChain Retriever mithilfe von Retriever-Abstraktionen, die mit pgvector in Vektorspeicher wie Pinecone, Qdrant oder Postgres eingebunden sind. Du entscheidest, wie Dokumente aufgeteilt, einbettet, Einbettungen gespeichert und Ergebnisse zum Zeitpunkt der Abfrage ausgewählt werden. Diese Flexibilität ist leistungsstark, überträgt dem Entwickler jedoch mehr Verantwortung für die Optimierung von LangChain Kontextgröße, Reranking-Strategien und Caching-Richtlinien.
Du kontrollierst jeden Schritt. Dies funktioniert gut, wenn du bereits über eine vorgegebene Speicherebene verfügst oder eine benutzerdefinierte Logik für die Auswahl und Reihenfolge von Dokumenten benötigst. Aber das bedeutet auch, dass du mehr Infrastruktur selbst aufbaust und wartest.
LlamaIndex integriert diese Auswahlmöglichkeiten in seine Indexe. Du konfigurierst einmalig Indextypen, Chunking-Strategien und Abfrageweiterleitungen und verlässt dich dann auf das Framework, um Abfragen effizient weiterzuleiten. Dies wirkt sich direkt auf die Leistung von LlamaIndex aus, da das Framework die Token-Nutzung, das Caching und das Routing im Hintergrund optimiert. Es verwaltet die LlamaIndex-Kontextkonstruktion: welche Blöcke in welcher Reihenfolge und mit welchen Metadaten eingefügt werden sollen, um die Antworten fundiert zu halten und dabei im Kontext zu bleiben.
Der Abruf von LlamaIndex erfolgt über Abfrage-Engines, die Baumindexe durchlaufen, Vektorindexe durchsuchen oder Ergebnisse aus mehreren Indextypen kombinieren können. Das Framework übernimmt Reranking-, Filter- und Syntheseschritte, die du andernfalls manuell erstellen müsstest.
Die praktische Leistung hängt vom Caching, der Indexauswahl und dem Chunking ab. Mit LangChain stimmst du diese manuell ab. Mit LlamaIndex konfigurierst du sie einmalig über Indexparameter und Abfrageeinstellungen. Wenn du umfassende Kontrolle bevorzugst und bereits über eine Speicherstrategie verfügst, ist der Ansatz von LangChain genau das Richtige für dich. Wenn du den Abruf lieber als High-Level-Baustein behandelst und dich auf Schemata und Quellen konzentrieren möchtest, kannst du mit LlamaIndex in der Regel schneller produktiv arbeiten.
Lifecycle-Management und Tooling in LangChain und LlamaIndex
Moderne KI-Apps beschränken sich nicht nur auf den Bau eines Prototyps. Du benötigst Beobachtbarkeit, Versionierung, Rollback-Strategien und sichere Deployments. Hier kommen LangChain Tools und die umgebende Infrastruktur ins Spiel.
LangChain verfügt über ein breites Ökosystem: Rückrufe, Nachverfolgung und Integrationen mit LangSmith zur Überwachung und Auswertung. Diese LangChain Tools lassen dich die Token-Nutzung, Latenz und Agentenentscheidungen überprüfen und daraufhin Ketten auf Basis echter Kennzahlen verbessern. Du kannst nachverfolgen, welche Tools ein Agent aufgerufen hat, wie lange jeder Schritt gedauert hat und wo Fehler aufgetreten sind.
In Kombination mit der Protokollierung deiner Hosting-Umgebung (n8n-Workflow-Protokolle, Systemmetriken auf einem VPS) resultiert daraus ein solider Lebenszyklus. Du weißt, wann Ketten ausfallen, warum sie ausfallen und wie du sie reparieren kannst. Du kannst A/B-Tests für verschiedene Prompt-Vvorlagen oder Modellanbieter durchführen und messen, welche in der Produktion besser abschneiden.
Bei LlamaIndex liegt der Fokus der Tools auf der Analyse von Indexen und der Leistung von Abfragen. Du kannst untersuchen, wie oft bestimmte Dokumente abgerufen werden, Indexparameter optimieren und Auswertungsworkloads über Testabfragen ausführen. Dies ist besonders nützlich, wenn dein Hauptaugenmerk auf der Abrufqualität und nicht auf der Kettenlogik liegt.
Die Abrufqualität von LlamaIndex wirkt sich direkt darauf aus, ob deine Antworten akkurat sind. Das Framework stellt Tools bereit, um die Abrufpräzision zu messen, zu untersuchen, welche Segmente für eine bestimmte Abfrage ausgewählt wurden, und die Indexeinstellungen auf Grundlage dieser Ergebnisse anzupassen. Du kannst Indexe auch versionieren, sodass ein Zurücksetzen auf einen früheren Daten-Snapshot problemlos möglich ist.
Die Installation ist für beide Frameworks ähnlich. Die Installation von LlamaIndex beschränkt sich in der Regel auf die Ausführung von pip install llama-index sowie die Konfiguration von Modell- und Embedding-Anbietern. Die meisten Teams verbinden beide Frameworks in derselben Umgebung und verwenden dann ihre Überwachungstools sowie zusätzlich Standard-DevOps-Praktiken (CI/CD, Protokollierung, Warnungen).
LangChain mit n8n für End-to-End KI-Workflows
LangChain funktioniert am besten, wenn du es mit einer Workflow-Engine koppelst. n8n verarbeitet Trigger, Wiederholungsversuche und Integrationen, während sich LangChain um die Beurteilung, Eingabeaufforderungen und Agenten kümmert. Hier geht die n8n-LangChain-Integration von der Theorie in die Praxis über.
Stelle dir die LangChain-Integration mit n8n als eine Art „Gehirn“ für deine Automatisierungen vor. n8n zieht Daten aus CRMs, Ticket-Systemen oder internen APIs und übergibt diesen Kontext an LangChain-Ketten oder -Agenten. Beispiele hierfür sind das Zusammenfassen langer Kundentickets vor der Zuweisung, das Generieren von Follow-Up-E-Mails oder die Unterstützung von KI-Kopiloten für Betriebsteams.
Ein typischer Ablauf sieht so aus: n8n wird durch einen Webhook oder Zeitplan ausgelöst, ruft Daten von externen Systemen ab, sendet sie an einen LangChain-Endpunkt, empfängt eine strukturierte Antwort und leitet diese Antwort dann an Slack, E-Mail oder eine Datenbank weiter. Die Arbeitsteilung ist klar. n8n orchestriert den Workflow. LangChain kümmert sich um LLM-Beurteilungen und Tool-Nutzung.
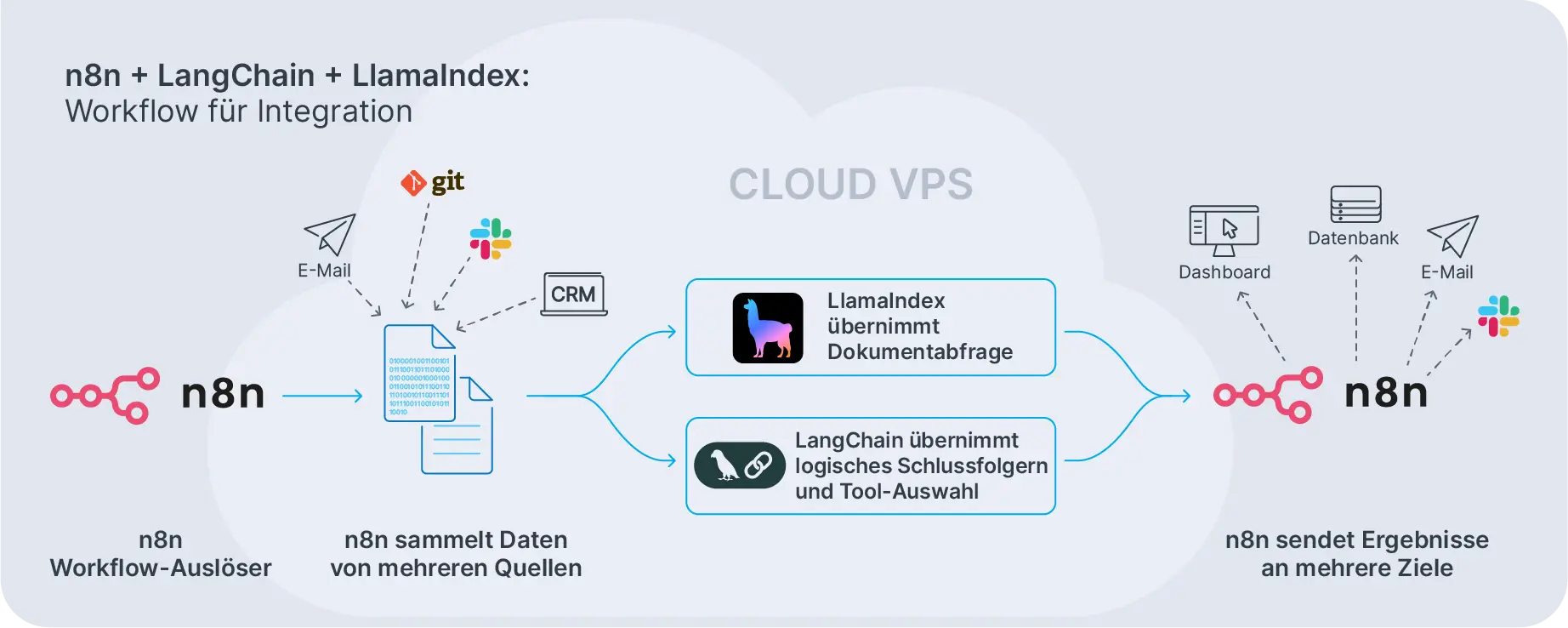
Ausführliche Beispiele mit verschiedenen Mustern kannst du in unserem Artikel über n8n KI-Workflows und erweiterte Integrationen erkunden. In diesen Setups orchestriert n8n den gesamten Prozess und ruft LangChain auf, wenn komplexe Beurteilungen oder LangChain-Eingabeaufforderungen erforderlich sind.
Diese Aufteilung funktioniert gut auf einem Contabo VPS. n8n, LangChain-Code und unterstützende Dienste laufen alle eng zusammen, minimieren die Latenz und vereinfachen die Bereitstellung. Du zahlst keine zusätzlichen Ausführungsgebühren und alles läuft auf der von dir kontrollierten Infrastruktur.
Wenn du dich fragst, wie du LangChain in n8n verwenden kannst, lautet die kurze Antwort: Stelle die LangChain-Logik über einen Code-Knoten, einen HTTP-Endpunkt oder einen Container-Microservice bereit und rufe sie dann als Teil deines Workflows von n8n-Knoten aus auf. Du kannst den LangChain-Abruf auch direkt in n8n-Codeknoten einbetten, wenn deine Workflows einfach genug sind.
LlamaIndex mit n8n für wissenszentrierte Automatisierungen
Wo LangChain Orchestrierungsintelligenz einbringt, liefert LlamaIndex verlässliches Wissen. Die Integration von n8n LlamaIndex ist sinnvoll, wenn deine Workflows auf akkurate Antworten bei großen Dokumentenmengen angewiesen sind.
Ein typisches Muster lautet: n8n verarbeitet Inhalte aus Quellen wie S3, Git-Repositories, Notion oder internen Wikis und löst dann Indexaktualisierungen in LlamaIndex aus. Das Framework verwaltet den Abruf und die LlamaIndex-Leistung, während n8n die Planung, Benachrichtigungen und nachgelagerte Aktionen übernimmt. Beispielsweise könnte ein wöchentlicher Job Indexe aus aktualisierten Richtliniendokumenten neu aufbauen und diese dann von Supportmitarbeitern über eine Chat-Schnittstelle abfragen lassen.
Dieses Setup funktioniert besonders gut, wenn du Kontrolle über deine Daten benötigst. Wenn deine Dokumente vertrauliche Verträge, interne Roadmaps oder regulierte Informationen enthalten, ist es wichtig, sowohl n8n als auch LlamaIndex auf einer von dir kontrollierten Infrastruktur auszuführen. Du übergibst Dokumente nicht an eine API eines Drittanbieters und musst nicht darauf Vertrauen, dass ein Cloud-Anbieter die Daten korrekt verwaltet.
Die n8n-LlamaIndex-Integration funktioniert normalerweise folgendermaßen: Definiere HTTP-Endpunkte oder Microservices rund um deine LlamaIndex-Abfrage-Engines und verwende dann den HTTP-Request-Knoten von n8n, um sie aus Workflows aufzurufen. Du kannst auch Indexaktualisierungen von n8n auslösen, wenn neue Dateien im Speicher landen oder ein Repository aktualisiert wird.
Wenn du diesen Stack unter deiner Kontrolle betreiben möchtest, kannst du n8n auf einem Contabo VPS selbst hosten und LlamaIndex ergänzend dazu bereitstellen. Dadurch verbleiben deine Dokumente, Einbettungen und Abfragen in der von dir verwalteten Infrastruktur.
Zu den Workflows, bei denen präzise Informationsabrufe entscheidend sind, zählen interne Dokumentations-Q&A, die Erstellung umfangreicher Berichte, Kundenwissensdatenbanken und Compliance-Prüfpfade. In all diesen Fällen sind Leistung und Abrufgenauigkeit wichtiger als die Orchestrierungsflexibilität. Deine Optimierung setzt den Fokus auf korrekte Antworten und nicht auf komplexe mehrstufige Beurteilungen.
LlamaIndex vs. LangChain FAQ
Wie funktioniert LlamaIndex?
LlamaIndex nimmt Daten aus Quellen wie Dateien, Datenbanken und APIs auf, konvertiert sie in Knoten, speichert sie in Indizes und stellt Abfrage-Engines bereit, die relevante Blöcke für das LLM abrufen. Der Schwerpunkt liegt auf dem Abruf, der Kontextaufbereitung und der Antwortsynthese und nicht auf der vollständigen Orchestrierung von Anwendungen.
Wie funktioniert LangChain?
LangChain stellt Komponenten wie Modelle, Prompts, Speicher, Tools und Ketten bereit, die du zu Anwendungen zusammenfügst. Du kannst Agenten hinzufügen, damit das Modell entscheiden kann, welches Tool oder welcher Schritt als nächstes ausgeführt werden soll, wodurch die Flexibilität für komplexe Aufgaben verbessert wird.
Wie wird LlamaIndex installiert?
Die meisten Setups installieren LlamaIndex mit pip install llama-index und ein wenig Konfiguration für Modelle und Einbettungen. Anschließend definierst du Datenkonnektoren, wählst Indextypen aus und verknüpfst Abfrage-Engines mit deiner Anwendung oder deinem Workflow-Tool.
Wie wird LangChain installiert?
In der Regel installierst du LangChain mit pip install langchain in Python oder den entsprechenden node.js-Paketen und konfigurierst dann Umgebungsvariablen für deine Modellanbieter. Von dort aus erstellst du Eingabeaufforderungen, Ketten und Agenten im Code und stellst sie über APIs, Hintergrundprozesse oder n8n-Integrationen bereit.
Wofür wird LlamaIndex hauptsächlich verwendet?
Häufige Anwendungsfälle von LlamaIndex umfassen Fragen und Antworten zur internen Dokumentation, rechtliche und vertragspolitische Assistenten, Wissensdatenbanken für den Support sowie jeden Workflow, bei dem ein präziser Abruf aus großen Dokumentensätzen wichtiger ist als komplexe, mehrstufige Beurteilung.
Was ist der n8n LlamaIndex-Integrationsprozess?
Um LlamaIndex mit n8n zu integrieren, stellst du LlamaIndex als Dienst oder Skript bereit, stellst Abfrageendpunkte bereit und rufst sie dann über n8n-Workflows mithilfe von HTTP-Knoten oder Codeknoten auf. Das Betreiben beider auf n8n-Hosting bei Contabo hält den Datenpfad unter deiner Kontrolle.
Wie verwendet man Langchain in n8n?
Du kannst LangChain in n8n verwenden, indem du Ketten oder Agenten in Codeknoten einbettest oder eine LangChain-Logik hinter einem HTTP-Endpunkt hostest und von n8n aus aufrufst. Dieses Muster passt gut, wenn n8n die Planung und Integration übernimmt, während sich LangChain um die Beurteilung und die LLM-Logik kümmert.
LangChain vs. LlamaIndex im Jahr 2026: Wofür solltest du dich entscheiden?
Wenn deine Priorität auf umfassender Orchestrierung, Tools und benutzerdefinierten Agenten liegt, ist LangChain der geeignete Startpunkt. Es gibt dir eine detaillierte Kontrolle über Prompts, Tools und Ketten und lässt sich gut mit Workflow-Engines wie n8n kombinieren, wenn du eine vollständige End-to-End-Automatisierung benötigst.
Wenn fundierte Antworten für dich Vorrang vor deinen eigenen Daten haben, ist LlamaIndex normalerweise die bessere erste Wahl. Es übernimmt Indexing, Weiterleitung und Synthese, sodass du dich auf die Auswahl relevanter Quellen konzentrieren kannst und nicht darauf, wie du sie zusammenfügst.
Bei vielen größeren Projekten wählt man nicht nur eines aus. Teams verwenden LlamaIndex als Abruf- und Wissensschicht, LangChain als Agenten- und Orchestrierungsschicht und n8n als Workflow-Schicht, die auf einem VPS oder Dedicated Server ausgeführt wird. Diese Kombination sorgt dafür, dass die Kosten vorhersehbar sind, du die Daten unter Kontrolle hast und sich der technische Aufwand auf die Lösung realer Probleme konzentriert, anstatt ständig die gleiche Infrastruktur neu zu erstellen.
Denke bei der Bewertung von LangChain vs. LlamaIndex darüber nach, wo die Komplexität in deinem Projekt liegt. Wenn es um mehrstufige Beurteilungslogik und den Einsatz von Tools geht, beginne mit LangChain. Wenn es um den Datenzugriff und die Qualität des Abrufs geht, beginne mit LlamaIndex – und wenn du beides benötigst, setze sie gemeinsam ein und lass jedes seine Stärke ausspielen.
