
Ejecutar grandes modelos de lenguaje solía significar APIs en la nube, facturación por token y confiar tus datos a terceros. Ollama cambió todo eso para mejor. Es una herramienta de código abierto que hace que ejecutar LLMs en tu propio hardware sea tan simple como instalar cualquier otro paquete.
La integración de n8n y Ollama te ofrece algo realmente útil: flujos de trabajo impulsados por IA que funcionan completamente en la infraestructura que controlas. Tus instrucciones permanecen locales. Las respuestas se generan en tu propio VPS. No hay límites de uso que drenen lentamente tu presupuesto. Para proyectos serios sobre IA y automatización, esta combinación lleva las cosas a un nuevo nivel.
Esta guía cubre qué hace Ollama, cómo funciona la maquinaria internamente y los pasos prácticos para integrarlo en flujos de trabajo de n8n que no se conectan a la red.
¿Qué es Ollama? Conceptos clave
Ollama es una plataforma de código abierto que simplifica la ejecución de grandes modelos de lenguaje localmente. En lugar de llamar a las APIs de OpenAI o Anthropic, descargas modelos en tu servidor y ejecutas inferencias allí. La gestión de modelos, el servicio y la optimización están todos integrados, por lo que no tienes que pasar semanas construyendo esa infraestructura tú mismo.
Las principales características de Ollama se centran en la accesibilidad. La gestión de modelos funciona a través de comandos simples: ollama pull llama3.2 descarga un modelo, ollama run llama3.2 comienza una conversación. Detrás de esos comandos se encuentra un servidor API que otras aplicaciones pueden llamar. Ese es tu punto de integración con n8n.
El rendimiento de Ollama depende de tu hardware, pero la herramienta optimiza la inferencia automáticamente. Gestiona la carga de modelos, la gestión de memoria y la utilización de GPU sin ajustes manuales. Un modelo de 7B parámetros funciona razonablemente en CPUs de consumo. Los modelos más grandes se benefician de las GPUs, pero no las requieren estrictamente.
Aquí es donde la seguridad de Ollama se vuelve interesante: la inferencia ocurre en tu infraestructura. Tus indicaciones nunca tocan APIs externas, y los archivos de modelo viven en tu disco. Las respuestas se generan localmente, sin tocar los servidores de otros. Para equipos que manejan datos sensibles o que operan bajo requisitos de cumplimiento, esto cambia fundamentalmente el perfil de riesgo en comparación con LLMs en la nube. Creemos que esto importa más que la mayoría de las comparaciones de pruebas.
La plataforma admite docenas de modelos, como Llama, Mistral, Gemma y DeepSeek. Puedes ejecutar múltiples modelos simultáneamente y cambiar entre ellos por prompt, eligiendo el tamaño y la capacidad del modelo adecuados para cada tarea en lugar de forzar todo a través de un único endpoint.
¿Cómo funciona Ollama por dentro?
Ollama comienza a trabajar cuando descargas un modelo. Descarga archivos de modelo, los almacena localmente y los hace disponibles para su servidor API. Cuando llega un prompt, Ollama carga el modelo en la memoria (o lo mantiene cargado para prompts posteriores), ejecuta la inferencia y devuelve el resultado.
¿Dónde almacena Ollama los modelos? Viven en una estructura de directorio específica. En Linux, generalmente es ~/.ollama/models/. Cada modelo consiste en archivos de pesos, configuración y metadatos. Modelos grandes pueden ocupar varios gigabytes. El espacio en disco importa cuando estás ejecutando múltiples modelos.
El servidor API expone un endpoint REST que acepta indicaciones y devuelve respuestas. Este endpoint se convierte en el punto de integración para herramientas como n8n. Cuando envías JSON con tus indicaciones y parámetros, Ollama lo procesa a través del modelo y recibes texto de vuelta. También admite streaming, por lo que las respuestas pueden llegar token por token en lugar de hacerte esperar a la finalización completa.
La gestión de memoria ocurre automáticamente. Ollama carga modelos a demanda y los descarga cuando aumenta la presión de memoria. Incluso 8 GB de RAM son suficientes para manejar modelos de 7B cómodamente. Modelos más grandes generalmente necesitan más memoria o versiones cuantizadas.
La aceleración por GPU es opcional pero beneficiosa. Si tienes una GPU disponible, Ollama la detecta y deriva el procesamiento allí, lo que acelera significativamente la inferencia para modelos más grandes. La inferencia solo con CPU todavía funciona para muchos casos de uso, particularmente para modelos más pequeños.
¿Por qué ejecutar Ollama en un VPS en lugar de en la nube?
Los modelos de precios de Ollama en la nube generalmente implican cargos por token o por hora que escalan con el uso. Una indicación de 1,000 palabras con una respuesta de 500 palabras podría costar unos pocos centavos. Parece razonable hasta que ejecutas 10,000 prompts mensuales y de repente estás pagando cientos. Ollama autoalojado en un VPS cambia completamente ese modelo de costos.
Con un VPS de Ollama, tu costo mensual es el servidor. Eso es todo. Ejecuta 100 o 100,000 prompts; la factura se mantiene igual. No hay cargos basados en uso que se vayan acumulando. No hay facturas sorpresas cuando el tráfico aumenta porque alguien compartió tu aplicación en Reddit.
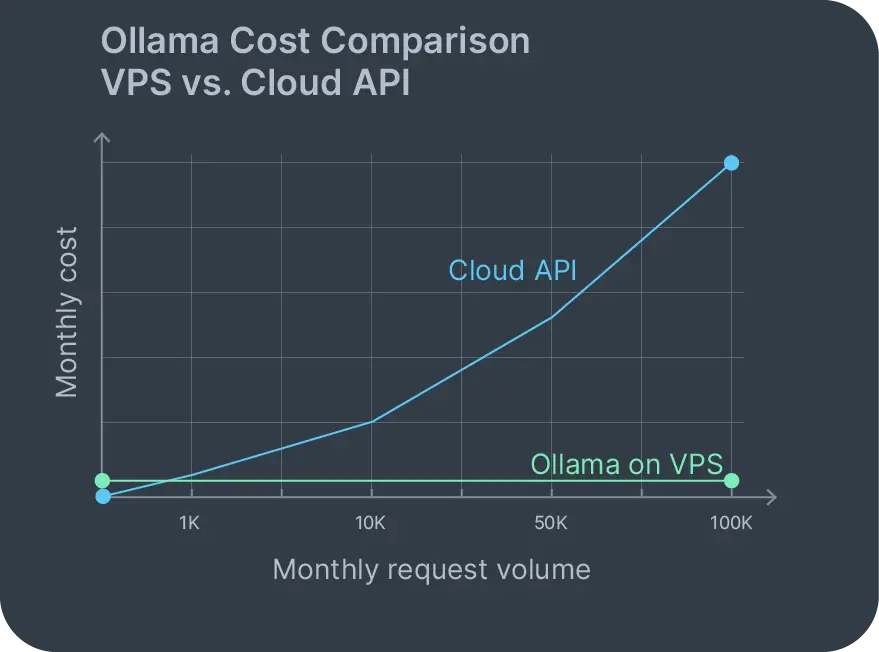
La privacidad de los datos es el otro factor importante. Existen opciones de servicio en la nube de Ollama, pero reintroducen el problema de confianza que intentabas evitar. Cuando ejecutas Ollama autoalojado, tus datos nunca abandonan tu infraestructura. Las solicitudes de soporte al cliente, documentos internos, código propietario: todo permanece en tu VPS durante la inferencia.
El cumplimiento se vuelve más sencillo también. El RGPD significa que necesitas saber dónde se procesan tus datos. La HIPAA restringe cómo se mueve la información de salud protegida. Ejecutar Ollama localmente te mantiene dentro de esos límites sin necesidad de negociar acuerdos complejos de procesamiento de datos con proveedores de la nube que pueden o no cumplirlos.
También controlas las actualizaciones. Los nuevos modelos se lanzan con frecuencia. Con una configuración autoalojada, descargas el nuevo modelo y lo pruebas de inmediato. No hay que esperar a que los proveedores de nube lo ofrezcan. No hay bloqueo de proveedor que determine a qué modelos puedes acceder o cuándo.
El hardware es importante para las cargas de trabajo de IA: necesitas suficientes núcleos de CPU, RAM y potencialmente acceso a GPU. Contabo ofrece una gama de planes de servidor optimizados para IA y aprendizaje automático con configuraciones adecuadas para ejecutar múltiples modelos y manejar prompts de inferencia concurrentes sin problemas. Por supuesto, puedes ejecutar Ollama en cualquier VPS, VDS o Servidor Dedicado de tu elección.
Eligir un proveedor de VPS Ollama
Ejecutar un VPS de Ollama con éxito requiere que el hardware coincida con tu carga de trabajo. La configuración mínima viable es algo como nuestro Cloud VPS 10: 4 núcleos de vCPU, 8 GB de RAM y 75 GB de almacenamiento. Eso maneja modelos de 7B parámetros razonablemente. Para una configuración más cómoda, podrías actualizar a un Cloud VPS 30 con 8 núcleos de vCPU, 24 GB de RAM y 200 GB de almacenamiento, que ejecuta modelos más grandes y atiende múltiples prompts concurrentes sin cuellos de botella.
El almacenamiento es importante porque los modelos son grandes. Llama3 7B ocupa aproximadamente 4 GB. Mixtral 8x7B se acerca a 50 GB. ¿Ejecutando varios modelos? El almacenamiento se acumula rápidamente. Los discos NVMe ayudan: cargar modelos desde el disco es más rápido, reduciendo la latencia de inicio cuando un modelo frío necesita iniciarse.
Una GPU no es obligatoria, pero cambia el rendimiento notablemente. Una GPU de gama media como la A4000 reduce considerablemente el tiempo de inferencia para modelos más grandes. Para flujos de trabajo de producción atendiendo a múltiples usuarios, las GPUs justifican su costo. Para herramientas internas con uso más ligero, la inferencia de CPU funciona bien. Explora la Nube GPU de Contabo para ver qué puedes añadir a tu servidor.
El ancho de banda de la red afecta la configuración inicial. Descargar modelos grandes requiere descargar gigabytes a través de la red. Después de eso, la inferencia local no toca la red a menos que estés integrando con servicios externos a través de n8n. Sin embargo, esa descarga inicial del modelo se beneficia de conexiones de red rápidas y estables.
Ejecutar Ollama junto a otras herramientas autoalojadas tiene sentido. Empareja Nextcloud autoalojado para almacenamiento de archivos con Ollama para análisis de documentos. Añade n8n para automatización de flujos de trabajo. Despliega todo en una instancia de Cloud VPS de Nextcloud si los recursos lo permiten, o distribúyelo entre varios servidores dependiendo de la carga y cómo quieras aislar los servicios. Ambas aplicaciones están disponibles en cualquier VPS o VDS de Contabo con instalación gratuita de 1 clic.
Paso a Paso: Desplegar Ollama en un VPS
Cómo instalar Ollama en Linux es sencillo. Inicia sesión en tu VPS y ejecuta el script de instalación:
curl -fsSL https://ollama.com/install.sh | sh Esto descarga Ollama, lo instala y comienza el servicio. En Ubuntu, Debian o la mayoría de las distribuciones modernas de Linux, funciona sin dependencias adicionales.
Después de que se complete la instalación, verifica que Ollama esté en ejecución:
ollama --version Deberías ver el número de versión. Ahora descarga tu primer modelo:
ollama pull llama3.2 Esto descarga Llama 3.2 (7B parámetros) y lo almacena localmente. El tiempo de descarga depende de la velocidad de tu red y del tamaño del modelo. Llama 3.2 ocupa alrededor de 4 GB, así que espera unos minutos en una conexión decente.
Cómo ejecutar Ollama después de descargar un modelo:
ollama run llama3.2 Esto inicia una sesión interactiva donde puedes probar prompts. Escribe una pregunta, presiona Enter y observa el flujo de respuesta. Sal con /bye.
Para ejecutar DeepSeek con Ollama en un VPS, el proceso es idéntico:
ollama pull deepseek-coder
ollama run deepseek-coder Los modelos de DeepSeek se especializan en generación y análisis de código. Ejecutarlos localmente significa que tus bases de código propietarias nunca abandonan tu infraestructura durante tareas de análisis o generación. Eso es muy importante si trabajas con algo que haría que tu equipo legal se pusiera nervioso.
¿Dónde almacena Ollama los modelos en tu sistema? Verifica la ruta predeterminada:
ls ~/.ollama/models Cada modelo vive en su propio subdirectorio con pesos, configuraciones y metadatos. ¿Gestionando el espacio en disco? Aquí es donde se acumulan los modelos.
El servidor API se inicia automáticamente y escucha en localhost:11434 por defecto. Ponlo a prueba con curl:
curl http://localhost:11434/api/generate -d '{
"model": "llama3.2",
"prompt": "Why is the sky blue?"
}'Deberías obtener una respuesta JSON con el texto generado enviado de regreso. Este endpoint es lo que n8n llamará para la integración.
Para uso en producción, considera ejecutar Ollama detrás de un proxy inverso si necesitas acceso externo. Pero para la integración con n8n en el mismo VPS, el acceso local es suficiente y más seguro: no necesitas exponer puertos que no tengas que exponer.
Si estás específicamente interesado en modelos de DeepSeek para aplicaciones de IA empresariales, Contabo también ofrece soluciones de IA DeepSeek autoimplementadas que están diseñadas para un rendimiento óptimo.
Requisitos previos para la integración de n8n y Ollama en un VPS
Antes de conectar la integración de n8n y Ollama, necesitas tener ambas herramientas instaladas y accesibles. Ollama ya está en ejecución si seguiste la sección anterior. Ahora instala n8n.
El camino más rápido es Docker:
docker run -d --name n8n \
-p 5678:5678 \
-v ~/.n8n:/home/node/.n8n \
n8nio/n8n O instálalo a través de npm si lo prefieres:
npm install n8n -g
n8n start Una vez que n8n esté en ejecución, accede a él en http://your-vps-ip:5678. Crea una cuenta. Estás listo para construir flujos de trabajo.
También podrías optar por instalar n8n usando nuestra opción gratuita de 1 clic, pero ten en cuenta que esto deberá configurarse primero en un nuevo servidor (o a través de una reinstalación destructiva en uno existente) seguida de la instalación manual de Ollama como arriba. Obtén más información sobre autoimplementación de n8n en un VPS de Contabo.
Cómo integrar Ollama con n8n requiere confirmar el acceso a la red. Si ambos servicios se ejecutan en el mismo VPS, la API de Ollama en localhost:11434 ya es accesible. Prueba esto desde la perspectiva de n8n creando un flujo de trabajo simple de solicitud HTTP:
- Añade un nodo de activación manual
- Añade un nodo de prompt HTTP
- Establece el método en POST
- URL:
http://localhost:11434/api/generate - Cuerpo: JSON con modelo y prompt
- Ejecuta el flujo de trabajo
Si la respuesta incluye texto generado, la conectividad funciona. Si falla, verifica que el servicio de Ollama esté en ejecución (systemctl status ollama) y escuchando en el puerto esperado.
Cómo conectar Ollama a n8n se vuelve más fácil con los nodos dedicados de Ollama de n8n. En lugar de crear prompts HTTP manualmente, puedes usar el nodo del modelo de chat de Ollama que maneja el formato de la API automáticamente.
Ejemplo de flujo de trabajo: Automatización de tareas con n8n y Ollama
Construir un flujo de trabajo de n8n y Ollama se vuelve práctico una vez que ambos servicios se comunican. Aquí hay un ejemplo del mundo real: análisis de correo electrónico automatizado y generación de respuestas para soporte al cliente.
La estructura del flujo de trabajo:
- El nodo de activación de correo electrónico observa una bandeja de entrada
- Extraer el contenido de nuevos correos electrónicos
- Enviar el contenido del correo electrónico a Ollama con un prompt
- Analizar la respuesta de Ollama
- Ruta hacia la acción apropiada
En n8n, esto se ve así:
Nodo de activación: Activador de correo electrónico (IMAP)
- Configurar para observar [email protected]
- Activar en nuevos mensajes no leídos
Nodo del modelo de chat de Ollama:
- Modelo: llama3.2
- Prompt: «Analiza este correo electrónico de atención al cliente y genera una respuesta. Correo: {{$json.body}}»
- Temperatura: 0.7 para creatividad equilibrada
Nodo IF: Verificar el sentimiento de la respuesta
- ¿Problema complejo? Ruta a un humano.
- ¿Sencillo? Preparar respuesta automática.
Nodo de envío de correo: Enviar respuesta generada
- Solo se ejecuta para casos sencillos
- Incluye un aviso de que la respuesta fue generada por IA

Este flujo de trabajo de n8n Ollama se ejecuta completamente en tu VPS. Los correos electrónicos de los clientes nunca llegan a APIs externas. Las respuestas generadas permanecen locales hasta que las envíes explícitamente. Tu bandeja de entrada de soporte no se convierte en datos de entrenamiento para el modelo de otra persona.
Cómo usar Ollama con n8n para estos flujos de trabajo implica pensar en prompts y parámetros. La temperatura controla la creatividad: valores más altos producen una salida más variada, valores más bajos producen resultados más deterministas. La longitud del contexto limita cuánto texto puedes enviar por prompt. La elección del modelo afecta tanto la capacidad como la velocidad.
Los flujos de trabajo de moderación de contenido también funcionan bien. Monitorear aplicaciones de chat y filtrar mensajes a través de Ollama para detectar contenido problemático y marcar para revisión. Todo sucede localmente. Las comunicaciones sensibles no salen de tu infraestructura durante la moderación, lo que importa si estás tratando con discusiones de empleados o reclamos de clientes.
La generación de contenido en redes sociales es otra aplicación práctica. Programar desencadenadores, enviar prompts a Ollama basados en tu calendario de contenido, generar variantes de publicaciones y almacenar para revisión. Los equipos de marketing pueden generar opciones por lotes sin que los costos por token de la API afecten su presupuesto.
Ejecutar Ollama autoalojado a través de flujos de trabajo n8n elimina la facturación basada en el uso del cómputo. Experimenta libremente. Alterna los prompts decenas de veces. Procesar altos volúmenes durante períodos pico. Tu costo se mantiene fijo en la tarifa de hosting VPS.
Preguntas frecuentes de Ollama
¿Cómo instalar Ollama en Linux?
Ejecutar el script de instalación: curl -fsSL https://ollama.com/install.sh | sh. Esto instala Ollama y comienza el servicio automáticamente en la mayoría de las distribuciones de Linux. Después de la instalación, verifica con ollama --version.
¿Cómo ejecutar Ollama?
Después de obtener un modelo con ollama pull model-name, inícialo con ollama run model-name para pruebas interactivas, o llama a la API en http://localhost:11434/api/generate para acceso programático. El enfoque de API es lo que utilizan los flujos de trabajo de n8n.
¿Dónde almacena Ollama los modelos?
Los modelos se almacenan en ~/.ollama/models/ en sistemas Linux. Cada modelo ocupa varios gigabytes dependiendo de la cantidad de parámetros y quantización. Verifica este directorio si estás administrando el espacio en disco o solucionando problemas de modelos faltantes.
¿Cómo conectar Ollama a n8n?
Instala ambas herramientas en el mismo VPS. Ollama escucha en localhost:11434 por defecto. En n8n, usa el nodo del modelo de chat de Ollama y configúralo para apuntar a http://localhost:11434. Prueba la conectividad con un flujo de trabajo simple antes de construir automatizaciones complejas.
¿Cómo usar Ollama con n8n?
Construye flujos de trabajo utilizando el editor visual de n8n. Agrega un nodo de modelo de chat de Ollama, configura tu modelo y prompt, luego conéctalo a nodos desencadenadores (webhooks, horarios, observadores de archivos) y nodos de acción (enviar correo, actualizar base de datos, publicar en API). Los prompts pueden incluir variables de pasos de flujo de trabajo previos para contenido dinámico.
Conclusión
Ollama hace que el despliegue local de LLM sea accesible para equipos que no tienen experiencia en infraestructura de aprendizaje automático. Combinado con la automatización de flujos de trabajo de n8n, estás construyendo sistemas impulsados por IA que se ejecutan completamente en tu propio hardware.
Costes fijos. Datos que nunca salen de tu VPS. Modelos que controlas. Estos beneficios importan más que los puntos de referencia de rendimiento teóricos o listas de características en presentaciones de marketing.
Los pros y los contras de Ollama se desglosan de manera predecible. Pros: previsibilidad de costes, privacidad de datos, simplificación del cumplimiento, libertad para experimentar sin límites de uso. Contras: gestionas la infraestructura, el rendimiento depende de tus elecciones de hardware, eres responsable de mantener los modelos actualizados. Para la mayoría de los equipos que se autoalojan en un VPS, esos compromisos favorecen el despliegue local.
Ollama autoalojado emparejado con n8n crea flujos de trabajo que no filtran datos ni te sorprenden con facturas de API. La automatización de soporte al cliente, el análisis de documentos, la generación de contenido y la revisión de código suceden localmente, en servidores que ya estás pagando.
Los requisitos de un Ollama VPS son sencillos: CPU o GPU adecuada dependiendo de tus elecciones de modelo, suficiente RAM para tus modelos seleccionados y suficiente almacenamiento para los archivos de modelos. Como ya mencionamos, Contabo ofrece configuraciones adecuadas para estas cargas de trabajo, incluyendo opciones de GPU para equipos que ejecutan modelos más grandes a gran escala.
Ejecutar ambas herramientas en el mismo VPS mantiene la latencia de red al mínimo y simplifica el despliegue. Ya sea que estés procesando documentos propietarios, generando respuestas a clientes o construyendo copilotos de IA internos, la integración de n8n y Ollama te da las piezas para construirlo sin dependencias externas o bloqueo de proveedores.
La infraestructura está lista. Las herramientas son de código abierto. Tus flujos de trabajo de IA pueden ejecutarse localmente, de manera privada, a costos predecibles. Comienza a integrar Ollama en tus automatizaciones y ve lo que es posible.
