
Elegir entre LlamaIndex y LangChain se trata menos de elegir el «mejor» framework y más de entender cuál coincide con la forma en la que estás construyendo. Ambos te ayudan a pasar de modelos de lenguaje en bruto a sistemas de IA en producción, pero están en diferentes capas de la pila y destacan en diferentes lugares.
Esta guía de LlamaIndex vs LangChain adopta un enfoque práctico. Cubriremos arquitectura, patrones de recuperación, compromisos de rendimiento, herramientas y cómo cada framework trabaja con n8n autohospedado en un VPS. Al final, sabrás si tu proyecto necesita herramientas orientadas a la orquestación, infraestructura orientada a datos o ambas corriendo en paralelo.
Los desarrolladores que evalúan LlamaIndex vs LangChain generalmente provienen de dos direcciones. O bien necesitan ayuda para orquestar prompts, herramientas, y razonamiento de varios pasos, o necesitan una forma confiable de conectar un LLM a documentos privados y bases de datos. LangChain se inclina más hacia la orquestación y los agentes. LlamaIndex (anteriormente GPT Index) es un framework de datos construido para que la generación aumentada por recuperación sea más fácil de implementar y operar.
En 2026, los equipos rara vez despliegan modelos en bruto. Usan frameworks para gestionar cadenas de LangChain, memoria, tuberías de recuperación, y evaluación. Entender cómo LlamaIndex y LangChain piensan sobre el contexto, los agentes, y las herramientas te ayuda a decidir si comenzar con uno, el otro, o combinarlos desde el primer día.
La mayoría de los proyectos reales no obligan a una decisión de uno u otro. Muchas pilas de producción utilizan LlamaIndex como la capa de conocimiento, LangChain como la capa de orquestación, y n8n como el motor de flujo de trabajo que los une en un VPS o Servidor Dedicado.
¿Qué es LangChain?
LangChain es un framework para construir aplicaciones impulsadas por LLM que conectan modelos de lenguaje con herramientas, fuentes de datos, y flujos de trabajo de múltiples pasos. Es un conjunto de herramientas que descompone el comportamiento de IA complejo en bloques de construcción componibles en lugar de meterlo todo en un único prompt.
Esos bloques de construcción son los componentes de LangChain. Los más comunes incluyen modelos, plantillas de prompts, memoria, recuperadores, y analizadores de salida. Los combinas en cadenas de LangChain, donde cada paso utiliza un LLM o herramienta para avanzar la tarea. Una cadena podría recuperar documentos, resumirlos, generar una respuesta, y luego registrar el resultado. Cada pieza se conecta a la siguiente, igual que los eslabones de una cadena.
Encima de las cadenas están los agentes de LangChain. Estos introducen toma de decisiones. Dado un objetivo y un conjunto de herramientas, un agente elige qué herramienta llamar a continuación, observa el resultado, y repite hasta que la tarea esté completada. Los agentes funcionan bien cuando las tareas implican lógica ramificada, APIs externas, y razonamiento de múltiples pasos que no puedes predecir de antemano.
Los prompts y plantillas de LangChain definen cómo estructuras las solicitudes al modelo. En lugar de codificar prompts, creas plantillas con variables que se llenan durante la ejecución. Esto hace que los prompts sean reutilizables y más fáciles de versionar. Los modelos de LangChain son integrables: OpenAI, Anthropic, Google o LLMs locales se adaptan a la misma abstracción, permitiéndote ajustar el costo y el rendimiento sin reescribir tu flujo de trabajo.
Instalar LangChain encaja con los flujos de trabajo normales de Python o node.js. Lo agregas a través de gestores de Python o node.js, configuras proveedores de modelos utilizando variables de entorno o archivos de configuración, y luego conectas cadenas o agentes a tus servicios. A partir de ahí, los expones detrás de APIs que n8n u otras herramientas de flujo de trabajo pueden llamar.
¿Qué es LlamaIndex?
Mientras LangChain se centra en la orquestación, LlamaIndex se centra en los datos. Funciona como un framework de datos para conectar tus documentos, bases de datos, y APIs a LLMs utilizando índices flexibles y motores de consulta. Potencia la generación aumentada por recuperación convirtiendo tu contenido en conocimiento estructurado que el modelo puede consultar de manera confiable.
Los principales componentes de LlamaIndex son conectores de datos, analizadores de nodos, índices, y motores de consulta. Ingiere datos de fuentes como S3, Postgres, sistemas de archivos, o APIs, divídelos en nodos, y luego construye índices. Las opciones incluyen índices vectoriales, índices de lista, índices de árbol, índices de palabras clave, e índices de gráfico. Cada uno interviene en velocidad, precisión, y complejidad de manera diferente.
En el tiempo de consulta, LlamaIndex dirige las consultas a través de estos índices y sintetiza respuestas. El marco maneja la selección de fragmentos, clasificación y ensamblaje de contexto para que obtengas pasajes relevantes dentro de la ventana de contexto del modelo sin construir manualmente ese flujo (pipeline) cada vez.
Las versiones recientes también añaden agentes de LlamaIndex, que ejecutan planes de múltiples pasos sobre tus índices y herramientas. Pero el marco aún mantiene el acceso y recuperación de datos como la narrativa principal. Si tu mayor problema es «Tengo muchos documentos y necesito respuestas precisas,» LlamaIndex suele ser el lugar para comenzar.
El contexto de LangChain y los modelos de LangChain pueden integrarse con los recuperadores de LlamaIndex, y muchos equipos ejecutan ambos marcos en paralelo. LangChain maneja la orquestación y el enrutamiento de herramientas; LlamaIndex maneja la ingestión de datos, indexación, y recuperación. Esta división del trabajo funciona bien cuando necesitas tanto flexibilidad como confiabilidad.
LlamaIndex también ofrece diferentes tipos de índices para diferentes casos de uso. Los índices vectoriales funcionan bien para búsqueda semántica. Los índices de árbol optimizan para documentos jerárquicos. Los índices de palabras clave manejan escenarios de coincidencia exacta. Elige el tipo de índice basado en la estructura de tus datos y patrones de consulta, y luego deja que el framework optimice la recuperación y síntesis de respuestas.
LangChain vs LlamaIndex: diferencias arquitectónicas principales
Comparar LangChain vs LlamaIndex significa observar cómo cada uno estructura una aplicación de IA. LangChain se construye en torno a prompts, herramientas, y agentes. LlamaIndex se construye en torno a conectores de datos, índices, y motores de consulta. Ambos pueden dar lugar a resultados finales similares, pero el camino que sigues a través de cada framework es diferente.
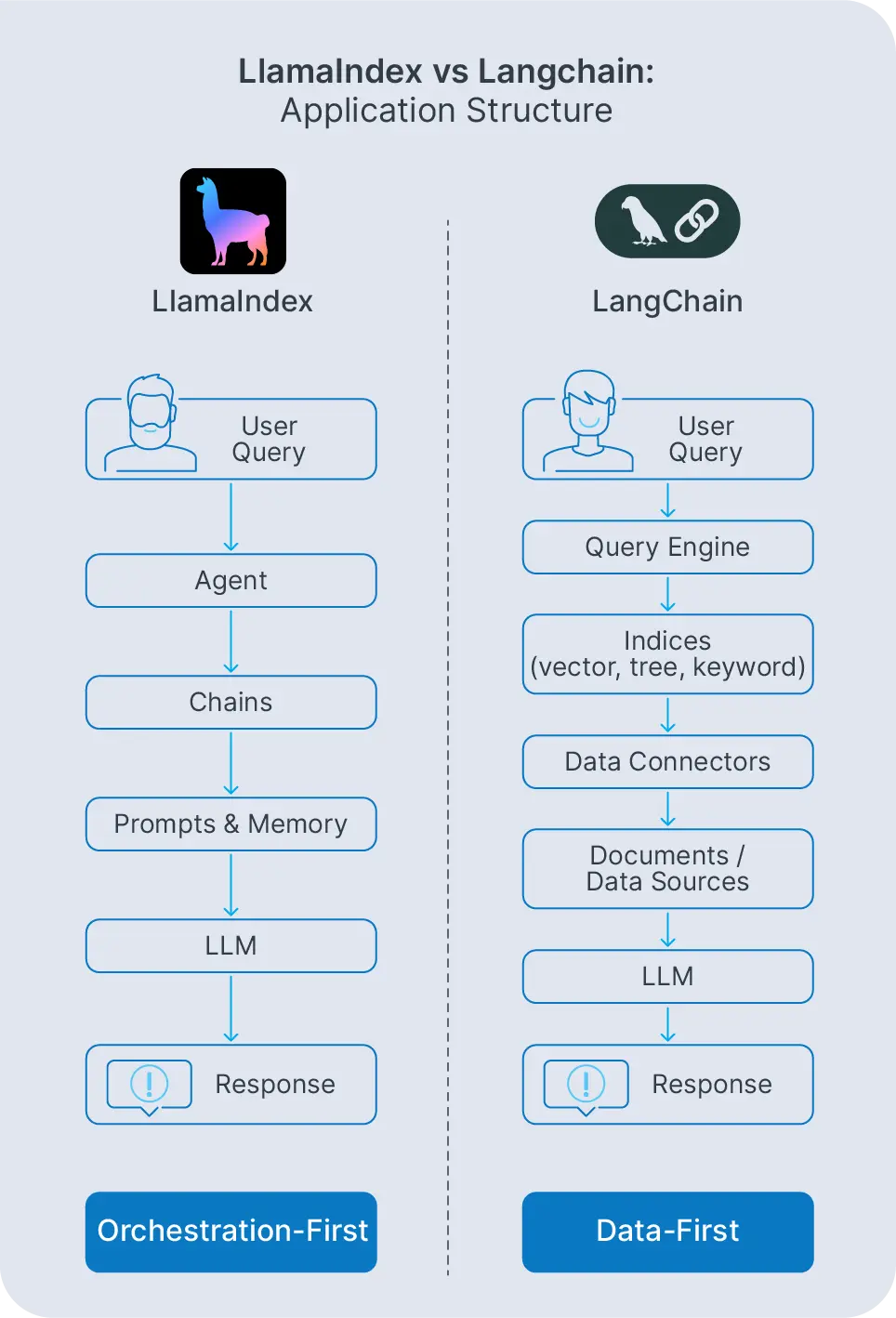
Con LangChain, los prompts y plantillas de LangChain definen cómo hablas al modelo. Esos prompts están conectados en cadenas de LangChain que orquestan llamadas a modelos, herramientas, y recuperadores, a menudo con componentes de memoria almacenando el historial de conversación o el contexto específico del usuario. Las cadenas se ejecutan de forma secuencial o condicional, dependiendo de cómo las configures.
Los modelos de LangChain son intercambiables. Puedes intercambiar OpenAI por Anthropic o Google sin reescribir la lógica de la aplicación. Esta abstracción es importante cuando estás optimizando costos o probando nuevos modelos. Cambia una línea de configuración en lugar de refactorizar todo tu código.
Los agentes de LangChain se sitúan encima de las cadenas. Estos agentes deciden qué herramienta llamar a continuación de un grupo de opciones: búsqueda en la web, consultas a bases de datos, APIs personalizadas u operaciones con archivos. Son excelentes cuando las tareas implican lógica de ramificación y herramientas externas, como asistentes de investigación, bots de operaciones o copilotos de soporte al cliente.
LlamaIndex toma un camino diferente. Los agentes y motores de consulta de LlamaIndex viven encima de los índices. En lugar de orquestar muchas herramientas, orquestan cómo se accede a tus datos: qué índice consultar, cómo combinar resultados, cómo generar respuestas finales. El enfoque se mantiene en la recuperación y la gestión del conocimiento en lugar de la orquestación general.
LangChain puede conectarse a los recuperadores de LlamaIndex y LlamaIndex puede ejecutarse dentro de los agentes de LangChain. Muchos sistemas de producción utilizan ambos. Pero cuando amplías la vista, LangChain es principalmente un motor de orquestación, mientras que LlamaIndex es principalmente un motor de datos y recuperación. Los equipos que necesitan flexibilidad y respuestas fundamentadas generalmente los despliegan juntos en lugar de forzar una decisión de uno u otro.
LlamaIndex frente a LangChain: Recuperación, Contexto y Rendimiento
La recuperación y la gestión del contexto impulsan el rendimiento del mundo real de LangChain y LlamaIndex más que cualquier elección de modelo única. Ambos marcos pueden alimentar RAG, pero estructuran ese trabajo de manera diferente y hacen diferentes compensaciones.
En LangChain, ensamblas la recuperación utilizando abstracciones de recuperadores conectadas a almacenes de vectores como Pinecone, Qdrant o Postgres con pgvector. Decides cómo dividir documentos, incrustarlos, almacenar las incrustaciones y seleccionar resultados en el momento de la consulta. Esa flexibilidad es poderosa pero implica más responsabilidad para el desarrollador en la configuración de LangChain del tamaño del contexto, estrategias de reordenamiento y políticas de almacenamiento en caché.
Controlas cada paso. Esto funciona bien cuando ya tienes una capa de almacenamiento con opiniones o necesitas lógica personalizada sobre cómo se seleccionan y ordenan los documentos. Pero también significa que estás construyendo y manteniendo más infraestructura tú mismo.
LlamaIndex integra estas elecciones en sus índices. Configuras tipos de índices, estrategias de división y enrutamiento de consultas una vez, luego confías en el framework para enrutarlos de manera eficiente. Esto tiene un impacto directo en el rendimiento de LlamaIndex, ya que el framework optimiza el uso de tokens, el almacenamiento en caché y el enrutamiento de fondo. Gestiona la construcción de contexto de LlamaIndex: qué fragmentos incluir, en qué orden y con qué metadatos, para mantener las respuestas fundamentadas mientras se mantiene dentro de la ventana de contexto.
La recuperación de LlamaIndex ocurre a través de motores de consulta que saben cómo recorrer índices de árbol, buscar en índices de vectores o combinar resultados de múltiples tipos de índices. El framework maneja las etapas de reordenamiento, filtrado y síntesis que de otro modo construirías de forma manual.
El rendimiento práctico se reduce al almacenamiento en caché, elección de índices y división. Con LangChain, ajustas estos manualmente. Con LlamaIndex, los configuras una vez a través de parámetros de índice y configuraciones de consulta. Si te gusta el control de bajo nivel y ya tienes una estrategia de almacenamiento, el enfoque de LangChain se adapta. Si prefieres tratar la recuperación como un primitivo de alto nivel y enfocarte en esquemas y fuentes, LlamaIndex generalmente te hace más productivo, más rápido.
Gestión del Ciclo de Vida y Herramientas en LangChain y LlamaIndex
Las aplicaciones de IA modernas no se detienen en la construcción de un prototipo. Necesitas observabilidad, versionado, estrategias de reversión y despliegues seguros. Aquí es donde LangChain con sus herramientas e infraestructura circundante comienzan a importar.
LangChain viene con un amplio ecosistema: callbacks, rastreo e integraciones con LangSmith para monitoreo y evaluación. Estas herramientas de LangChain te permiten inspeccionar el uso de tokens, la latencia y las decisiones de los agentes, luego mejorar cadenas basándote en métricas reales. Puedes rastrear qué herramientas llamó un agente, cuánto tiempo llevó cada paso y dónde ocurrieron fallos.
Combinado con el registro de tu entorno de hosting (registros de flujo de trabajo de n8n, métricas del sistema en un VPS), esto forma una sólida historia de ciclo de vida. Sabes cuándo las cadenas fallan, por qué fallan y cómo solucionarlas. Puedes realizar pruebas A/B en diferentes plantillas de aviso o proveedores de modelos y medir cuál tiene un mejor rendimiento en producción.
En el lado de LlamaIndex, las herramientas de LlamaIndex se centran en la introspección de índices y el rendimiento de las consultas. Puedes explorar con qué frecuencia se recuperan documentos específicos, ajustar parámetros de índice y ejecutar cargas de trabajo de evaluación sobre consultas de prueba. Esto es especialmente útil cuando tu principal riesgo es la calidad de recuperación más que la lógica de cadena.
La calidad de recuperación de LlamaIndex impacta directamente si tus respuestas son precisas. El framework proporciona herramientas para medir la precisión de recuperación, inspeccionar qué fragmentos se seleccionaron para una consulta dada y ajustar configuraciones de índice basadas en esos resultados. También puedes versionar índices, así que volver a una instantánea de datos anterior es sencillo.
La instalación es similar para ambos frameworks. Instalar LlamaIndex generalmente se reduce a: pip install llama-index, más la configuración de modelos y proveedores de incrustaciones. La mayoría de los equipos conectan ambos frameworks en el mismo entorno, luego utilizan sus herramientas de observabilidad más las prácticas estándar de DevOps (CI/CD, registro, alertas) por encima.
LangChain con n8n para Flujos de Trabajo AI de Extremo a Extremo
LangChain funciona mejor cuando se combina con un motor de flujo de trabajo. n8n maneja desencadenadores, reintentos e integraciones; LangChain maneja razonamientos, avisos y agentes. Aquí es donde la integración de n8n y LangChain se vuelve práctica en lugar de teórica.
Piensa en la integración de LangChain con n8n como darle a tus automatizaciones un «cerebro». n8n extrae datos de CRM, sistemas de tickets o APIs internas y luego pasa ese contexto a las cadenas o agentes de LangChain. Los ejemplos incluyen resumir tickets de clientes largos antes de la asignación, generar correos electrónicos de seguimiento o potenciar copilotos de IA para equipos de operaciones.
Un flujo típico se ve así: n8n se activa en un webhook o un horario, extrae datos de sistemas externos, los envía a un endpoint de LangChain, recibe una respuesta estructurada y luego redirige esa respuesta a Slack, correo electrónico o una base de datos. La división del trabajo es clara. n8n orquesta el flujo de trabajo. LangChain se encarga del razonamiento LLM y del uso de herramientas.
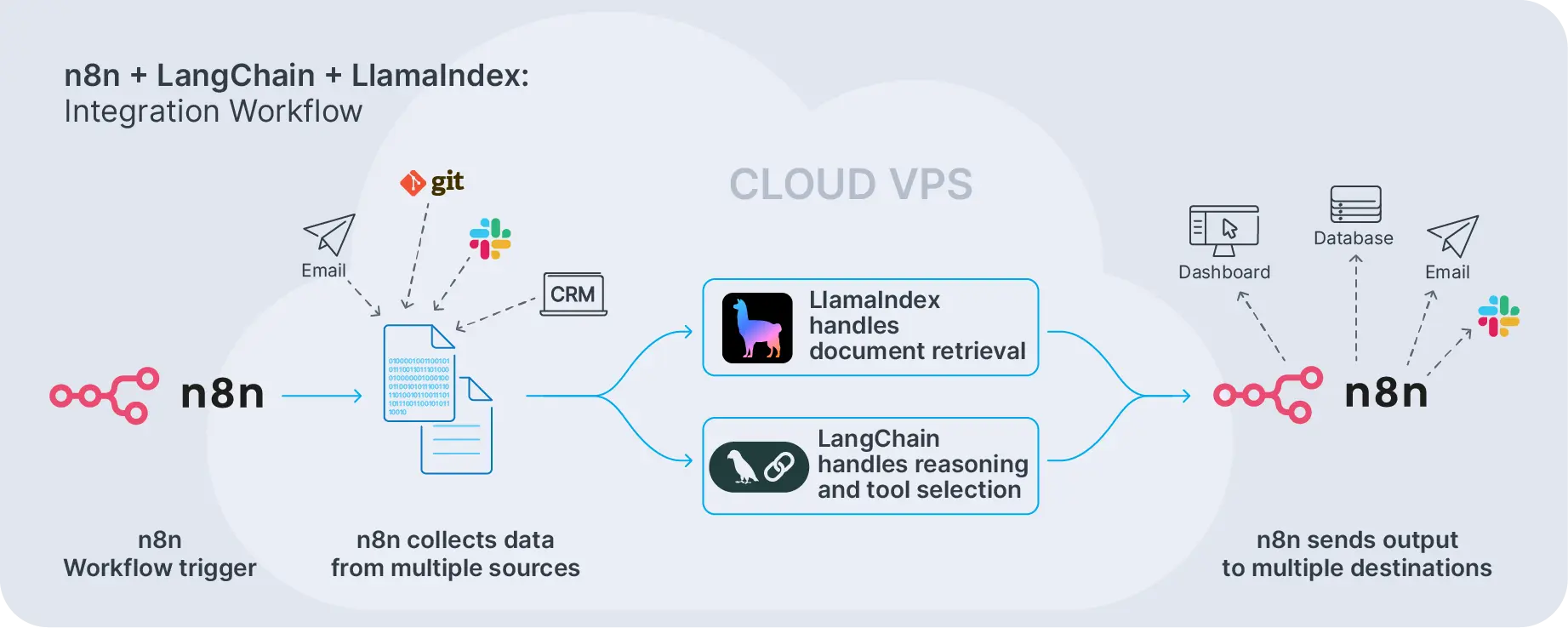
Para ejemplos más profundos, puedes explorar patrones descritos en nuestro artículo sobre flujos de trabajo de n8n AI e integraciones avanzadas. En esas configuraciones, n8n orquesta todo el proceso y llama a LangChain donde se requiere razonamiento complejo o avisos de LangChain.
Esta división funciona bien en un VPS de Contabo. n8n, el código de LangChain y los servicios de apoyo se ejecutan todos muy cerca, minimizando la latencia y simplificando el despliegue. No pagas tarifas adicionales de ejecución y todo se ejecuta en infraestructura que controlas.
Si te preguntas cómo usar LangChain en n8n, la versión corta es: expón la lógica de LangChain a través de un nodo de código, un endpoint HTTP o un microservicio contenedorizado y luego llámalo desde nodos de n8n como parte de tu flujo de trabajo. También puedes incrustar la recuperación de LangChain directamente en nodos de código de n8n si tus flujos de trabajo son lo suficientemente simples.
LlamaIndex con n8n para Automatizaciones Centradas en el Conocimiento
Donde LangChain trae inteligencia de orquestación, LlamaIndex aporta conocimiento confiable. La integración de n8n y LlamaIndex tiene sentido cuando tus flujos de trabajo dependen de respuestas precisas sobre grandes conjuntos de documentos.
Un patrón típico es: n8n ingiere contenido de fuentes como S3, repositorios de Git, Notion o wikis internos y luego activa actualizaciones de índice en LlamaIndex. El framework gestiona la recuperación y el rendimiento de LlamaIndex, mientras que n8n maneja la programación, notificaciones y acciones posteriores. Por ejemplo, un trabajo semanal podría reconstruir índices a partir de documentos de políticas actualizados y luego permitir que los agentes de soporte los consulten a través de una interfaz de chat.
Esta configuración funciona especialmente bien cuando necesitas control sobre tus datos. Si tus documentos incluyen contratos confidenciales, hojas de ruta internas o información regulada, ejecutar tanto n8n como LlamaIndex en infraestructura que controlas es importante. No estás entregando documentos a una API de terceros ni confiando en que un proveedor de nube maneje la residencia de datos correctamente.
La integración de n8n y LlamaIndex generalmente se reduce a esto: define endpoints HTTP o microservicios alrededor de tus motores de consulta de LlamaIndex y luego utiliza el nodo de Solicitud HTTP de n8n para llamarlos desde flujos de trabajo. También puedes activar actualizaciones de índice desde n8n cada vez que nuevos archivos se añaden al almacenamiento o un repositorio se actualiza.
Si deseas ejecutar este stack bajo tu control, puedes autoalojar n8n en un VPS de Contabo y desplegar LlamaIndex junto a él. Esto mantiene tus documentos, incrustaciones y consultas en infraestructura que gestionas.
Los flujos de trabajo donde la recuperación precisa es importante incluyen Q&A de documentación interna, generación de informes de formato largo, bases de conocimiento de clientes y auditorías de cumplimiento. En todos estos casos, el rendimiento y la precisión de recuperación importan más que la flexibilidad de orquestación. Estás optimizando para respuestas correctas, no para razonamiento complejo en múltiples pasos.
FAQ sobre LlamaIndex vs LangChain
¿Cómo funciona LlamaIndex?
LlamaIndex ingiere datos de fuentes como archivos, bases de datos y APIs, los convierte en nodos, los almacena en índices y expone motores de consulta que recuperan fragmentos relevantes para el LLM. Se centra en la recuperación, el ensamblaje de contexto y la síntesis de respuestas en lugar de la orquestación completa de la aplicación.
¿Cómo funciona LangChain?
LangChain proporciona componentes como modelos, indicaciones, memoria, herramientas y cadenas que conectas en aplicaciones. Puedes añadir agentes para que el modelo decida qué herramienta o paso ejecutar a continuación, mejorando la flexibilidad para tareas complejas.
¿Cómo instalar LlamaIndex?
La mayoría de las configuraciones instalan LlamaIndex con pip install llama-index y un poco de configuración para modelos y embeddings. Después de eso, defines conectores de datos, eliges tipos de índice y conectas motores de consulta en tu aplicación o herramienta de flujo de trabajo.
¿Cómo instalar LangChain?
Normalmente, instalas LangChain utilizando pip install langchain en Python o paquetes equivalentes de node.js, luego configuras las variables de entorno para tus proveedores de modelos. Desde allí, creas indicaciones, cadenas y agentes en código y los expones a través de APIs, trabajadores en segundo plano, o integraciones con n8n.
¿Cuáles son los principales casos de uso para LlamaIndex?
Los casos de uso comunes de LlamaIndex incluyen preguntas y respuestas de documentación interna, asistentes legales y de políticas, bases de conocimiento de soporte, y cualquier flujo de trabajo donde la recuperación precisa de grandes conjuntos de documentos sea más importante que el razonamiento complejo de múltiples pasos.
¿Cuál es el proceso de integración de n8n y LlamaIndex?
Para integrar LlamaIndex con n8n, despliegas LlamaIndex como un servicio o script, expones puntos finales de consulta, y luego los llamas desde flujos de trabajo de n8n usando nodos HTTP o nodos de código. Ejecutar ambos en hosting de n8n en Contabo mantiene el camino de datos bajo tu control.
¿Cómo usar langchain en n8n?
Puedes usar LangChain en n8n integrando cadenas o agentes dentro de nodos de código, o al alojar la lógica de LangChain detrás de un punto final HTTP y llamándolo desde n8n. Este patrón se adapta bien cuando n8n maneja la programación y las integraciones mientras LangChain maneja el razonamiento y la lógica de LLM.
Entonces, LangChain vs LlamaIndex en 2026: ¿Cuál deberías elegir?
Si tu prioridad es una orquestación rica, herramientas y agentes personalizados, LangChain es el punto de partida más sólido. Te proporciona un control detallado sobre las indicaciones, herramientas y cadenas, y se combina bien con motores de flujo de trabajo como n8n cuando necesitas una automatización completa de extremo a extremo.
Si tu prioridad son las respuestas fundamentadas sobre tus propios datos, LlamaIndex suele ser la mejor opción inicial. Maneja el indexado, el enrutamiento y la síntesis para que puedas enfocarte en qué fuentes importan, no en cómo unirlas.
En muchos proyectos serios, no eliges solo uno. Los equipos utilizan LlamaIndex como la capa de recuperación y conocimiento, LangChain como la capa de agente y orquestación, y n8n como la capa de flujo de trabajo ejecutándose en un VPS o Servidor Dedicado. Esa combinación mantiene los costos predecibles, los datos bajo tu control y el esfuerzo de ingeniería enfocado en resolver problemas reales en lugar de reconstruir constantemente la misma infraestructura.
Al evaluar LangChain vs LlamaIndex, piensa en dónde reside la complejidad en tu proyecto. Si está en razonamiento de múltiples pasos y uso de herramientas, comienza con LangChain. Si está en acceso a datos y calidad de recuperación, comienza con LlamaIndex. Y si está en ambos, despliégalo todo junto y deja que cada uno maneje lo que mejor hace.
